Lecture 14
Feature Store, Vector DB, Misc.
Amit Arora, Jeff Jacobs
Georgetown University
Fall 2025
Project Discussion
Any questions about the project presentation?
Any other project questions?
Feature Store
Data preparation accounts for about 80% of the work of data scientists
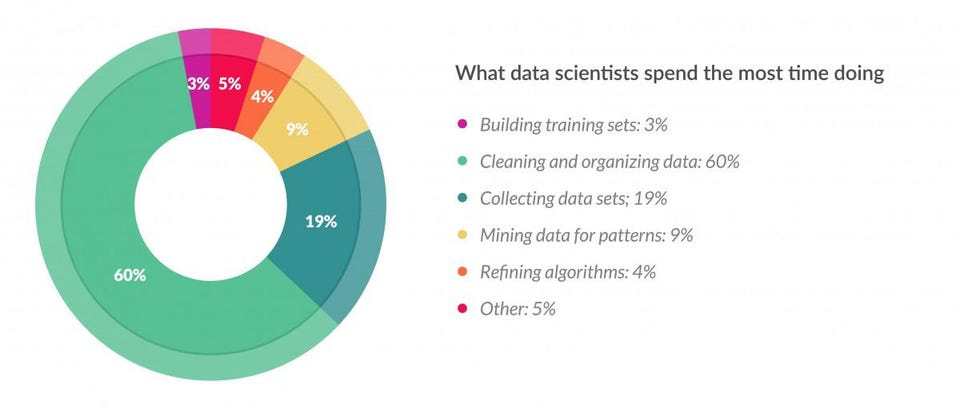 > Source: Forbes article
> Source: Forbes article
Why does this happen?
- Same set of data sources…
- Multiple different feature pipelines..
- Multiple ML models..
- But, an overlapping set of ML features..
- More problems…
- Feature duplication
- Slow time to market
- Inaccurate predictions
Solution…
Machine Learning Feature Store
- For a moment, think of the feature store as a database but for ML features.
- In a Feature Store
- Features are now easy to find (GUI, SDK)
- Feature transformations are reproducible (feature engineering pipelines can now refer to a consistent set of data)
- ML training pipeline has a reliable, curated, maintained data source to get training datasets rather than having to look at the data lake directly
- Low latency lookup for realtime inference
- Consistent features for training and inference
Feature Stores you can use
Vector Databases
- Store entities (text, images, audio, video, anything really..) represented as embeddings.
- Embeddings are numerical representations of entities in high dimensional spaces.
- Embeddings encode (semantic) meaning associated with the objects.
- Provide fast similarity search between entities (of course represented as vector embeddings).
- Focus is not on finding the exact match, but most similar matches.
Why do we need vector databases?
- Central to Generative AI apps.
- Extend the capabilities of LLMs.
- Avoid hallucinations.
- Use cases include
- Product search
- Troubleshooting and incident response
- Of course, RAG!
Algorithms for similarity searh
- k-Nearest Neighbor (k-NN)
- Approximate Nearest Neighbor