Lecture 11
Scale data processing workloads with Ray
Georgetown University
Fall 2025
Looking Back
- Intro to Hadoop and MapReduce
- Hadoop Streaming
- Dask
- Spark RDDs, DataFrames, SparkSQL, SparkML, SparkNLP
- Polars, DuckDB, RAPIDS
Future
- Project final report
Today
- Project Discussion
- Ray
Reviewing Prior Topics
AWS Academy
Credit limit - $100
Course numbers:
- Course #1 - 24178
- Course #2 - 27354
- Course #3 - 22802
- Course #4 - 26418
STAY WITH COURSE 24178 UNLESS YOU HAVE RUN OUT OF CREDITS OR >$90 USED!
Note that you will have to repeat several setup steps:
- security group
- EC2 keypair uploading (the AWS part only)
- sagemaker setup
- any S3 uploading or copying as well as bucket creation as necessary
- EMR configuration
Ray

Ray is an open-source unified compute framework that makes it easy to scale AI and Python workloads — from reinforcement learning to deep learning to tuning, and model serving. Learn more about Ray’s rich set of libraries and integrations.
Why do we need Ray?
To scale any Python workload from laptop to cloud
Remember the Spark ecosystem with all its integrations…
Hadoop (fault tolerance, resiliency using commodity hardware) -> Spark (in memory data processing) -> Ray (asynch processing, everything you need for scaling AI workloads)
What can we do with Ray?
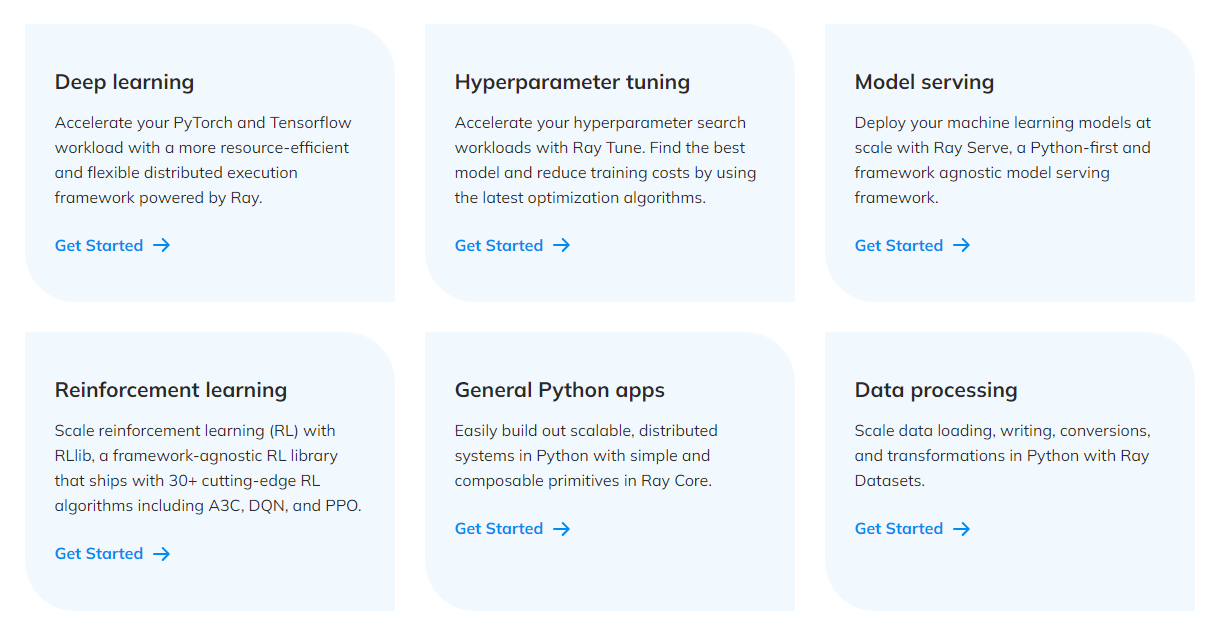
What comes in the box?
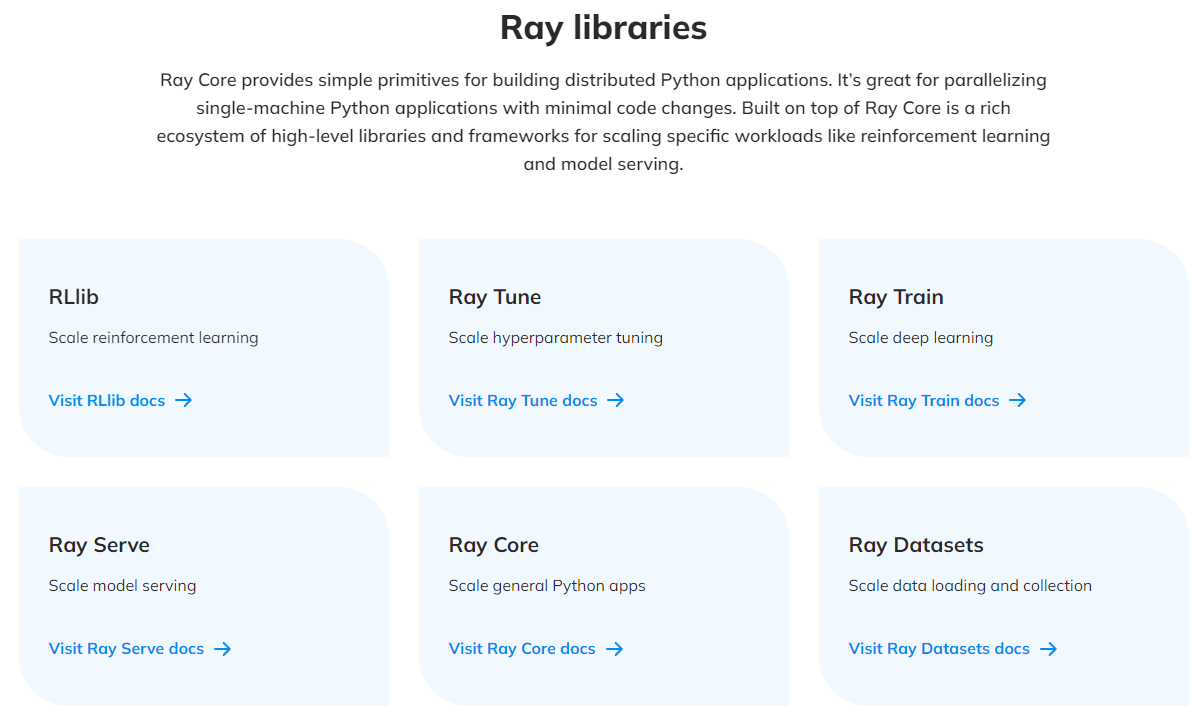
Our focus today …
Ray Core Ray Core provides a small number of core primitives (i.e., tasks, actors, objects) for building and scaling distributed applications.
Ray Datasets
Ray Datasets are the standard way to load and exchange data in Ray libraries and applications. They provide basic distributed data transformations such as maps (map_batches), global and grouped aggregations (GroupedDataset), and shuffling operations (random_shuffle, sort, repartition), and are compatible with a variety of file formats, data sources, and distributed frameworks.
Ray Core - Tasks
Ray enables arbitrary functions to be executed asynchronously on separate Python workers.
Such functions are called Ray remote functions and their asynchronous invocations are called Ray tasks.
```{python}
# By adding the `@ray.remote` decorator, a regular Python function
# becomes a Ray remote function.
@ray.remote
def my_function():
# do something
time.sleep(10)
return 1
# To invoke this remote function, use the `remote` method.
# This will immediately return an object ref (a future) and then create
# a task that will be executed on a worker process.
obj_ref = my_function.remote()
# The result can be retrieved with ``ray.get``.
assert ray.get(obj_ref) == 1
# Specify required resources.
@ray.remote(num_cpus=4, num_gpus=2)
def my_other_function():
return 1
# Ray tasks are executed in parallel.
# All computation is performed in the background, driven by Ray's internal event loop.
for _ in range(4):
# This doesn't block.
my_function.remote()
```Ray Core - Actors
- Actors extend the Ray API from functions (tasks) to classes.
- An actor is a stateful worker (or a service).
- When a new actor is instantiated, a new worker is created, and methods of the actor are scheduled on that specific worker and can access and mutate the state of that worker.
```{python}
@ray.remote(num_cpus=2, num_gpus=0.5)
class Counter(object):
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
return self.value
def get_counter(self):
return self.value
# Create an actor from this class.
counter = Counter.remote()
# Call the actor.
obj_ref = counter.increment.remote()
assert ray.get(obj_ref) == 1
```Ray Core - Objects
Tasks and actors create and compute on objects.
Objects are referred as remote objects because they can be stored anywhere in a Ray cluster
- We use object refs to refer to them.
Remote objects are cached in Ray’s distributed shared-memory object store
There is one object store per node in the cluster.
- In the cluster setting, a remote object can live on one or many nodes, independent of who holds the object ref(s).
Note
Remote objects are immutable. That is, their values cannot be changed after creation. This allows remote objects to be replicated in multiple object stores without needing to synchronize the copies.
Ray Core - Objects (contd.)
Ray Datasets
Ray Datasets are the standard way to load and exchange data in Ray libraries and applications.
They provide basic distributed data transformations such as
maps,globalandgrouped aggregations, andshuffling operations.Compatible with a variety of file formats, data sources, and distributed frameworks.
Ray Datasets are designed to load and preprocess data for distributed ML training pipelines.
Datasets simplify general purpose parallel GPU and CPU compute in Ray.
- Provide a higher-level API for Ray tasks and actors for such embarrassingly parallel compute, internally handling operations like batching, pipelining, and memory management.
Ray Datasets
- Create
- Transform
```{python}
import pandas as pd
# Find rows with spepal length < 5.5 and petal length > 3.5.
def transform_batch(df: pd.DataFrame) -> pd.DataFrame:
return df[(df["sepal length (cm)"] < 5.5) & (df["petal length (cm)"] > 3.5)]
transformed_dataset = dataset.map_batches(transform_batch)
print(transformed_dataset)
```- Consume
- Save