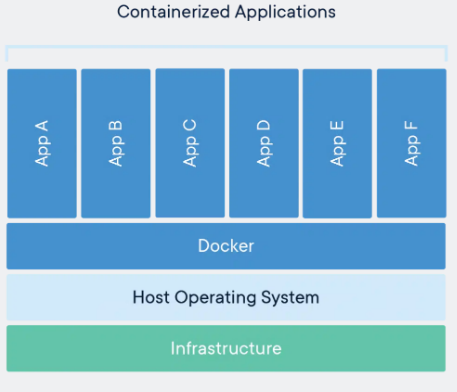
A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings.
Container images become containers at runtime and in the case of Docker containers – images become containers when they run on Docker Engine.
Dockerfile
# syntax=docker/dockerfile:1# adapted from https://www.philschmid.de/aws-lambda-with-custom-docker-image# https://docs.aws.amazon.com/lambda/latest/dg/python-image.htmlFROM public.ecr.aws/lambda/python:3.9# copy requirements file and install necessary packagesADD requirements.txt ${LAMBDA_TASK_ROOT}RUN pip3 install -r ${LAMBDA_TASK_ROOT}/requirements.txt --target "${LAMBDA_TASK_ROOT}"# Copy function code to docker containerCOPY app.py ${LAMBDA_TASK_ROOT}# app (name of py file)# handler (name of function to execute for lambda job)CMD [ "app.lambda_handler" ]
Data Engineering
What is Data Engineering?
As the scale of the data grew, the existing ETL processes alone were not sufficient, a separate discipline was needed for:
Collecting data
Managing storage
Cataloging
Making it available for applications such as analytics & machine learning)
Security
Lifecycle management
And more…
From Wikipedia: Data engineering refers to the building of systems to enable the collection and usage of data. This data is usually used to enable subsequent analysis and data science; which often involves machine learning. Making the data usable usually involves substantial compute and storage, as well as data processing and cleaning.
What do Data Engineers do?
Data engineers build systems that collect data from different sources and make this data available for analytics and ML application. This usually involves the following:
Acquisition: Finding all the different datasets around the business.
These could be available in databases, shared drives, ingested directly from IoT devices, external datasets, and more.
Cleansing: The raw data usually cannot be used as is, it needs to be cleaned.
Conversion: Since the data is coming from different sources, it would probably in different formats (database tables, CSV, JSON, custom). Needs to be converted into a common format (such as parquet) before it becomes usable.
Multiple datasets need to be joined together to answer a business question.
What do Data Engineers do (contd.)?
Disambiguation: How to interpret what the data means? Use a data catalog and then with the help of subject matter experts (often called Data Stewards) add meaningful description to the datasets.
Deduplication: Having a single source of truth!
Data Governance: for how long to store the data, how to enforce access controls (Principle of least privilege) etc.
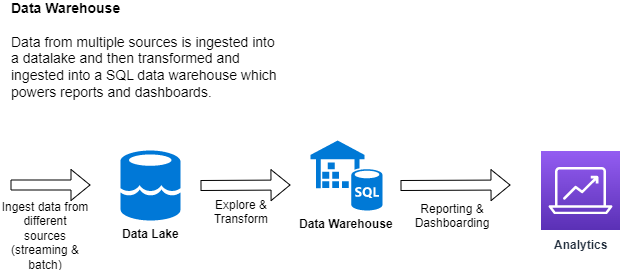
Once this is done, data may be stored in a central repository such as a data lake or data lakehouse. Data engineers may also copy and move subsets of data into a data warehouse.
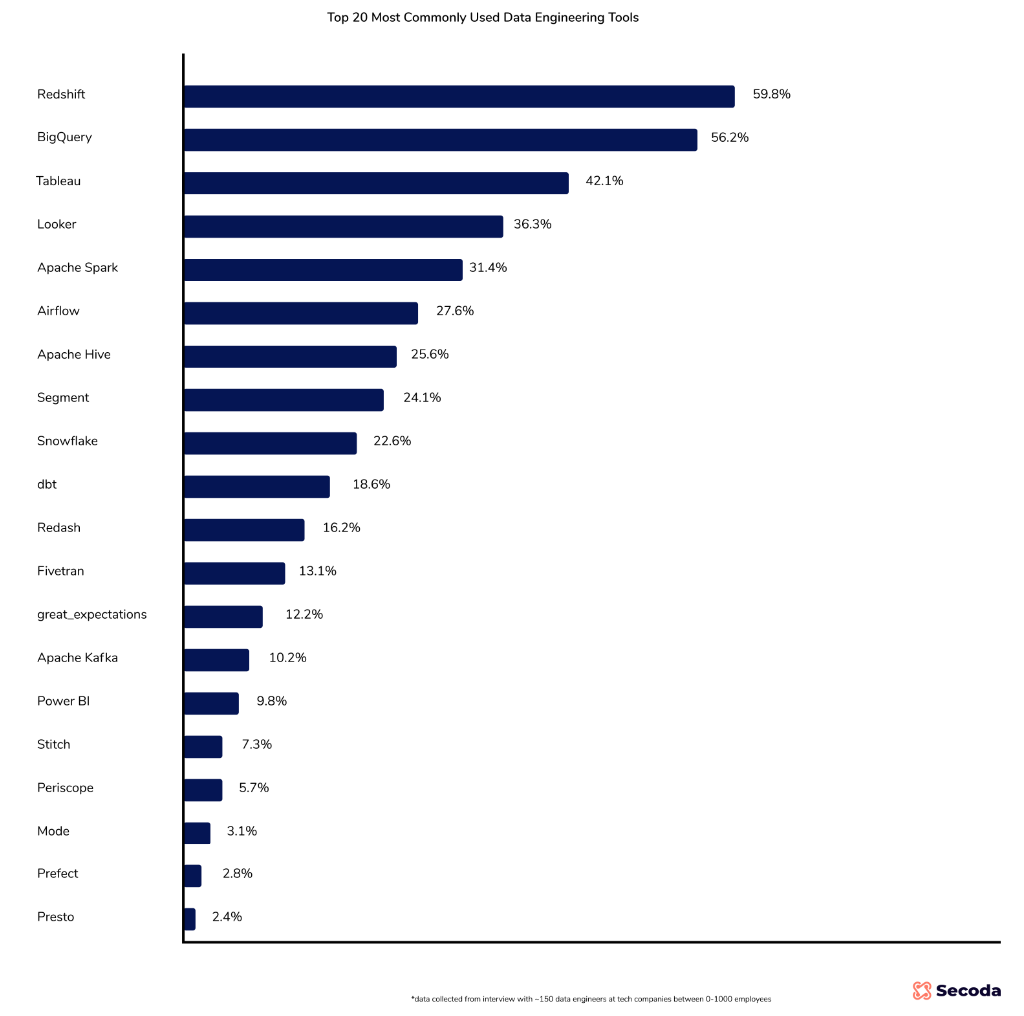
Data engineering tools & technologies
Data engineers work with a variety of tools and technologies, including:
ETL Tools: ETL (extract, transform, load) tools move data between systems. They access data, and then apply rules to “transform” the data through steps that make it more suitable for analysis.
SQL: Structured Query Language (SQL) is the standard language for querying relational databases.
Python: Python is a general programming language. Data engineers may choose to use Python for ETL tasks. Spark (pyspark) for Big Data, Apache Flink for streaming data.
Cloud Data Storage: Including Amazon S3, Azure Data Lake Storage (ADLS), Google Cloud Storage, etc.
Cloud Data Warehouses: Data ready for use by data scientists and analysts is stored in data warehouses, such as Amazon Redshift, Google BigQuery, Azure Data Warehouse, Snowflake etc.
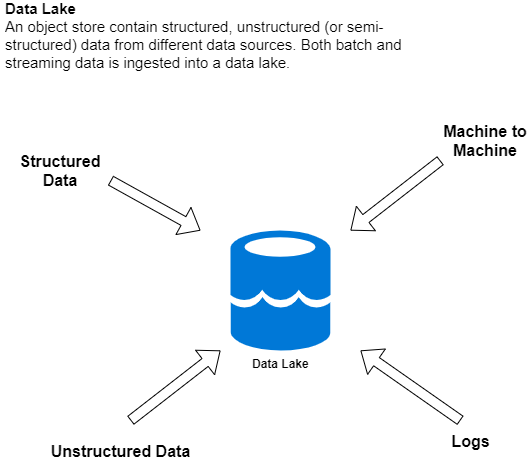
From Wikipedia: A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc., and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).
Data Lake (Cloud Provider Definitions)
Definitions in the wild (emphasis mine).
AWS
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
GCP
A data lake provides a scalable and secure platform that allows enterprises to: ingest any data from any system at any speed—even if the data comes from on-premises, cloud, or edge-computing systems; store any type or volume of data in full fidelity; process data in real time or batch mode; and analyze data using SQL, Python, R, or any other language, third-party data, or analytics application.
Azure
Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed, and do all types of processing and analytics across platforms and languages.
DataBricks
A data lake is a central location that holds a large amount of data in its native, raw format. Compared to a hierarchical data warehouse, which stores data in files or folders, a data lake uses a flat architecture and object storage to store the data.
Working with a Cloud Data Lake
A cloud data lake is setup using the cloud provider’s object store (S3, GCS, Azure Blob Storage).
Integration with data processing tools such as Spark, machine learning tools such as SageMaker, data warehouses such as RedShift and data cataloging tools.
They provide Fine Grained Access Control to the data.
Data Warehouses
From Wikipedia: In computing, a data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is a system used for reporting and data analysis and is considered a core component of business intelligence. DWs are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place that are used for creating analytical reports for workers throughout the enterprise.
Data Warehouse (Cloud Provider Definitions)
Definitions in the wild (emphasis mine).
AWS
A data warehouse is a central repository of information that can be analyzed to make more informed decisions. Data flows into a data warehouse from transactional systems, relational databases, and other sources, typically on a regular cadence. Business analysts, data engineers, data scientists, and decision makers access the data through business intelligence (BI) tools, SQL clients, and other analytics applications.
Azure
A data warehouse is a centralized repository of integrated data from one or more disparate sources. Data warehouses store current and historical data and are used for reporting and analysis of the data.
GCP
A data warehouse is an enterprise system used for the analysis and reporting of structured and semi-structured data from multiple sources, such as point-of-sale transactions, marketing automation, customer relationship management, and more.
Snowflake
A data warehouse (DW) is a relational database that is designed for analytical rather than transactional work. It collects and aggregates data from one or many sources so it can be analyzed to produce business insights.
Working with a Cloud Data Warehouse
All cloud providers provide a data warehouse solution that works in conjunction with their data lake solution.
In a data warehouse, Online analytical processing (OLAP) allows for fast querying and analysis of data from different perspectives. It also helps in pre-aggregating and pre-calculating the information available in the archive.
Integration with reporting and dashboarding tools such as Tableau, Grafana, Looker etc. and data analytics tools such as Spark and data cataloging tools.
They provide Fine Grained Access Control to the data.
Combining Data Lakes and Data Warehouses
Combine the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses to provide a single architecture that can enable business intelligence and machine learning on all data.
At some point we needed to think beyond relation databases, because: - Data became more and more complex (not all data is tabular, thinkin JSON data emitted by an IoT device). - Cost of storage decreased (everything did not need to be stored in the 3rd normal form) - More data on the cloud meant data needed to be placed across different servers (scale-out) - Data needed to be placed intelligently in geo locations of interest - And more…
From Wikipedia: A NoSQL (originally referring to “non-SQL” or “non-relational”) database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. Such databases have existed since the late 1960s, but the name “NoSQL” was only coined in the early 21st century, triggered by the needs of Web 2.0 companies. NoSQL databases are increasingly used in big data and real-time web applications. NoSQL systems are also sometimes called Not only SQL to emphasize that they may support SQL-like query languages or sit alongside SQL databases in polyglot-persistent architectures.
Types of NoSQL Databases
Over time, four major types of NoSQL databases emerged: document databases, key-value databases, wide-column stores, and graph databases.
Document databases store data in documents similar to JSON (JavaScript Object Notation) objects. Each document contains pairs of fields and values. The values can typically be a variety of types including things like strings, numbers, booleans, arrays, or objects.
Key-value databases are a simpler type of database where each item contains keys and values.
Wide-column stores store data in tables, rows, and dynamic columns.
Graph databases store data in nodes and edges. Nodes typically store information about people, places, and things, while edges store information about the relationships between the nodes.
Amazon DynamoDB, Apache Cassandra, Google Bigtable, Azure Tables
Graph databases
Amazon Neptune, Neo4j
As a data scientist, you would work with a NoSQL database through an SDK/API. Several programming languages are supported including Python, Java, Go, C++ etc.
Example of documents in a document database
Here is an example of a document inserted in a key-value/document database such as MongoDB.
Besides the general concepts about data lkakes, warehouses, different types of databases, there are some purpose built databases that are good to know about.
Splunk
Elasticsearch
DuckDB
Many many more…
Splunk
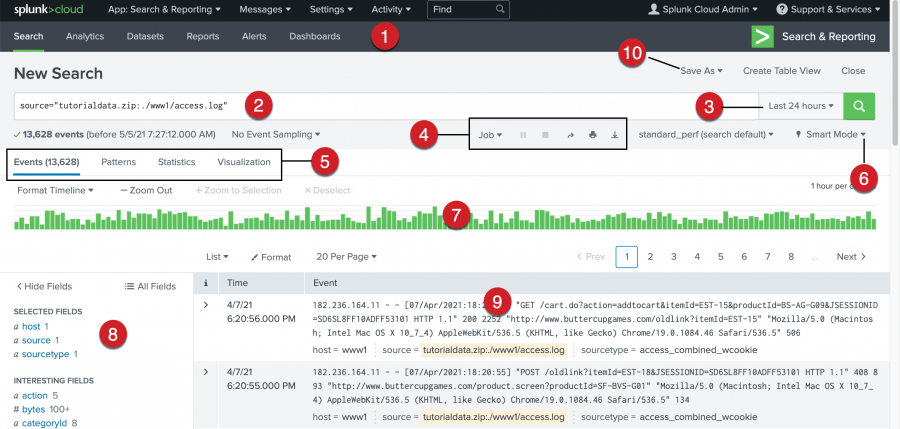
Splunk is a software platform to search, analyze and visualize the machine-generated data gathered from the websites, applications, sensors, devices etc. which make up your IT infrastructure and business. See https://www.splunk.com/.
The logfile we analyzed in assignment 4 s3://bigdatateaching/forensicswiki/2012_logs.txt, is the typical kind of data that gets ingested into Splunk.
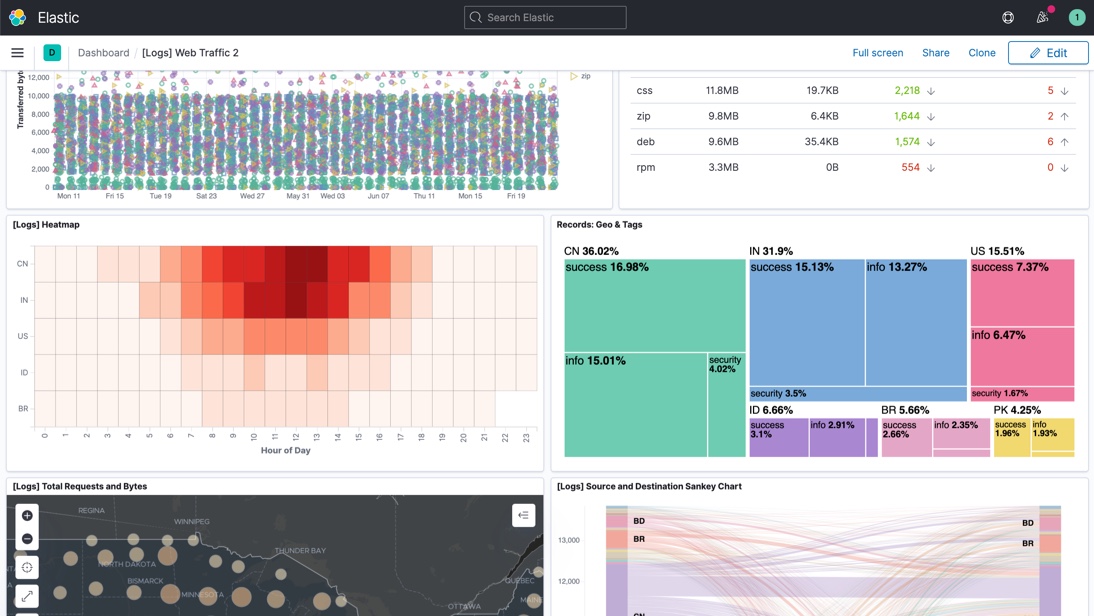
From https://www.elastic.co/what-is/elasticsearch, emphasis mine
Elasticsearch is a distributed, free and open search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Elasticsearch is built on Apache Lucene and was first released in 2010 by Elasticsearch N.V. (now known as Elastic).
Commonly referred to as the ELK Stack (after Elasticsearch, Logstash, and Kibana), the Elastic Stack now includes a rich collection of lightweight shipping agents known as Beats for sending data to Elasticsearch.
Data is inserted in Elasticsearch indexes as JSON documents using a REST API/SDK.
Image courtsey: https://www.elastic.co/kibana
DuckDB
DuckDB is an in-process SQL OLAP database management system.
It is like sqllite, but for analytics. What does this mean? It means that your database runs inside your process, there are no servers to manage, no remote system to connect to. Very snappy, easy to experiment with SQL like syntax.
DuckDB does vectorized processing i.e. loads chunks of data into memory (tries to keep everything in the CPU’s L1 and L2 cache) and is thus able to handle datasets bigger than the amount of RAM available.
DuckDB supports Python, R and a host of other languages.
When to use DuckDB: when you cannot use Pandas for rapid experimentation with Big Data, especially when combining DuckDB with Arrow.
When not to use DuckDB: DuckDB has a valuable but very niche use-case.
Further Reading
Please lookup these topics on Google for further reading. Not providing specific links here because they all point to vendor-specific products.