Lecture 13
Feature Store, Vector DBs, AI work
Amit Arora, Abhijit Dasgupta, Anderson Monken, and Marck Vaisman
Georgetown University
Fall 2023
Logistics and Review
Deadlines
Lab 7: Spark DataFrames Due Oct 10 6pmLab 8: SparkNLP Due Oct 17 6pmAssignment 6: Spark (Multi-part) Due Oct 23 11:59pmLab 9: SparkML Due Oct 24 6pmLab 10: Spark Streaming Due Oct 31 6pmProject: First Milestone: Due Nov 10 11:59pmLab 12: Dask Due Nov 14 6pm- Project: Peer Feedback Due Nov 20 11:59pm
- Project: NLP Milestone Due Nov 30 11:59pm
- Project: Final Delivery Due Dec 8 11:59pm
Look back and ahead
- Spark vs non-spark approaches
- Misc topics today
- Next week: Last class, wrapup, AMA, hang out at Tombs or Clubhouse
- Survey on tools
Feature Store
Data preparation accounts for about 80% of the work of data scientists
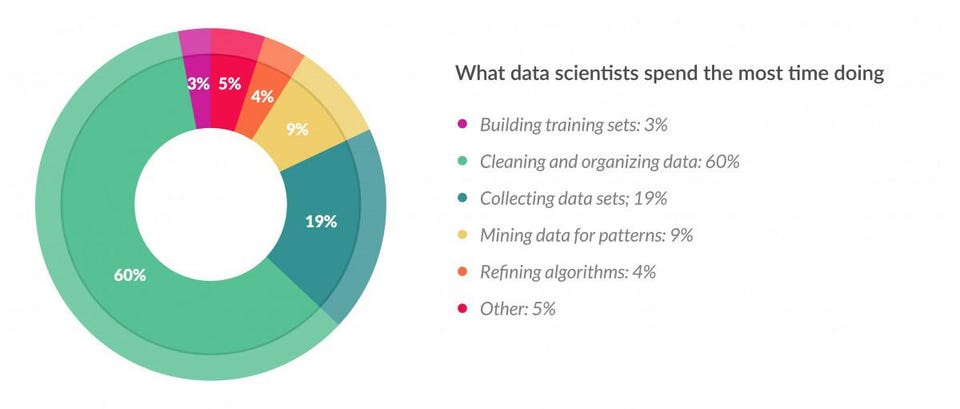 > Source: Forbes article
> Source: Forbes article
Why does this happen?
- Same set of data sources…
- Multiple different feature pipelines..
- Multiple ML models..
- But, an overlapping set of ML features..
- More problems…
- Feature duplication
- Slow time to market
- Inaccurate predictions
Solution…
Machine Learning Feature Store
- For a moment, think of the feature store as a database but for ML features.
- In a Feature Store
- Features are now easy to find (GUI, SDK)
- Feature transformations are reproducible (feature engineering pipelines can now refer to a consistent set of data)
- ML training pipeline has a reliable, curated, maintained data source to get training datasets rather than having to look at the data lake directly
- Low latency lookup for realtime inference
- Consistent features for training and inference
Feature Stores you can use
Vector Databases
Why do we need vector databases?
Algorithms for similarity search
- k-Nearest Neighbor (k-NN)
- Approximate Nearest Neighbor
Langchain and Vector DBs
Large scale data ingestion
Lab
DSAN 6000 | Fall 2023 | https://gu-dsan.github.io/6000-fall-2023/