Lecture 10
Spark Streaming
collect CAUTION

Up to now, we’ve worked with batch data
Processing large, already collected, batches of data.
How do we work with streams?
Processing every value coming from a stream of data. That is, data values that are constantly arriving
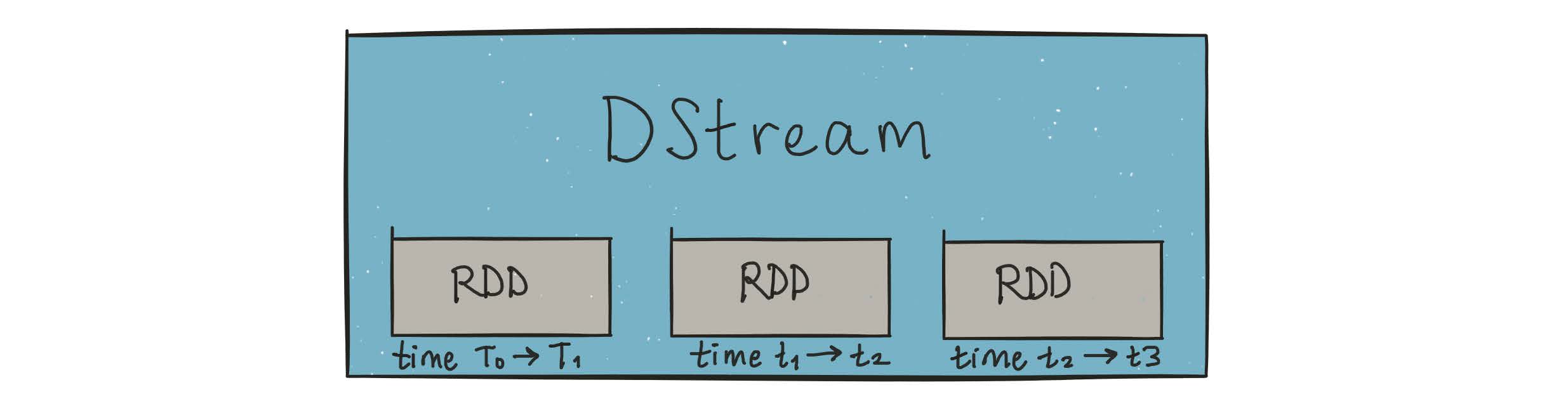
Spark solved this problem by creating DStreams using microbatching
DStreams are represented as a sequence of RDDs.
A StreamingContext object can be created from an existing SparkContext object.
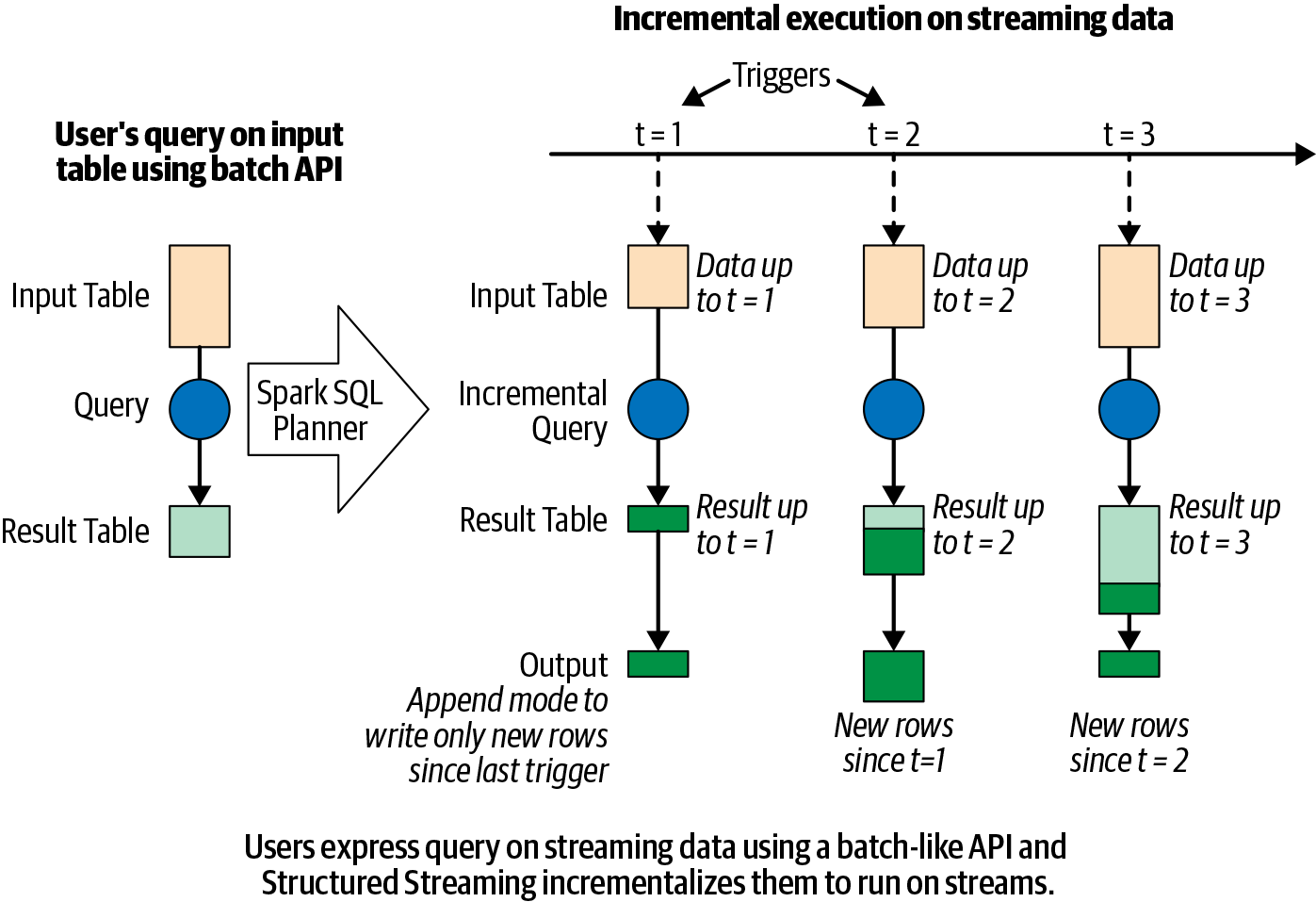
The Programming Model of Structured Streaming
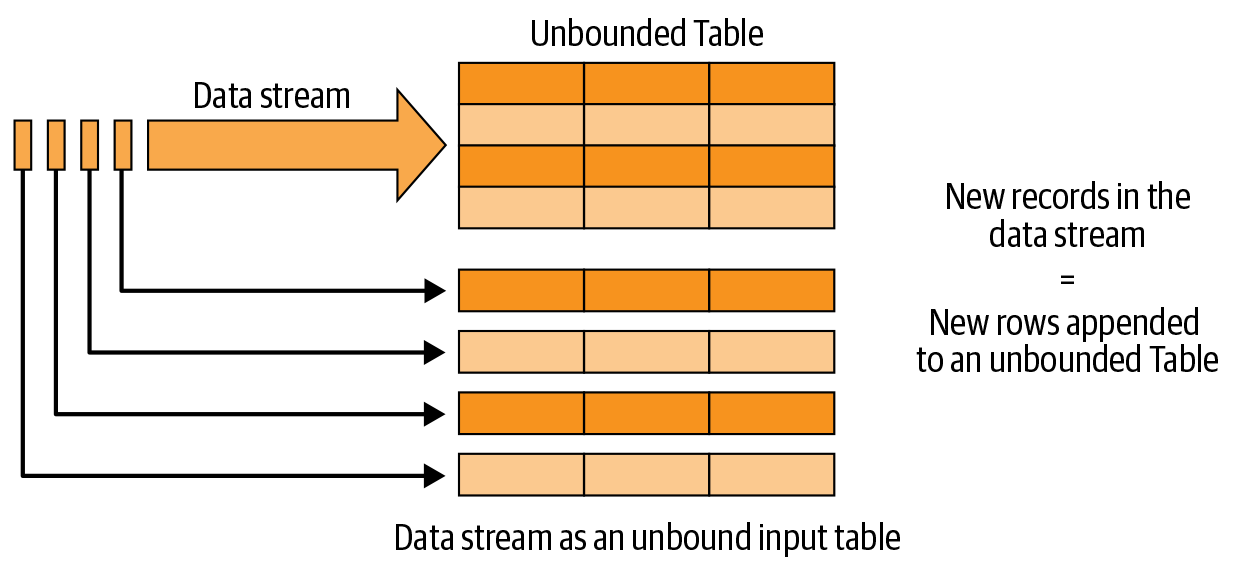
The Programming Model of Structured Streaming
- Every new record received in the data stream is like a new row being appended to the unbounded input table.
- Structured Streaming will automatically convert this batch-like query to a streaming execution plan. This is called incrementalization
- Structured Streaming figures out what state needs to be maintained to update the result each time a record arrive
- Finally, developers specify triggering policies to control when to update the results. Each time a trigger fires, Structured Streaming checks for new data (i.e., a new row in the input table) and incrementally updates the result.
Spark Streaming under the hood
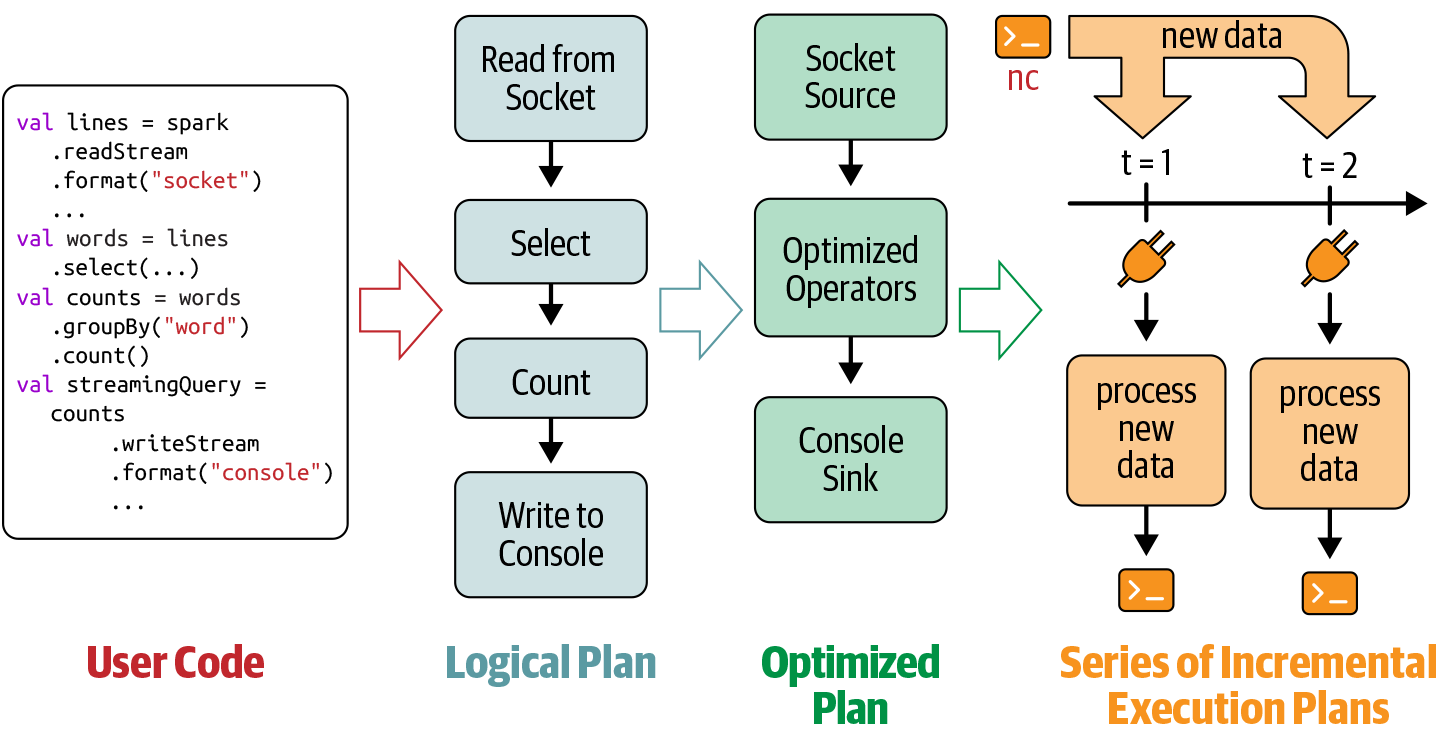
- Spark SQL analyzes and optimizes this logical plan to ensure that it can be executed incrementally and efficiently on streaming data.
- Spark SQL starts a background thread that continuously executes a loop
- This loop continues until the query is terminated
Spark Streaming under the hood
The loop
Based on the configured trigger interval, the thread checks the streaming sources for the availability of new data.
If available, the new data is executed by running a micro-batch. From the optimized logical plan, an optimized Spark execution plan is generated that reads the new data from the source, incrementally computes the updated result, and writes the output to the sink according to the configured output mode.
For every micro-batch, the exact range of data processed (e.g., the set of files or the range of Apache Kafka offsets) and any associated state are saved in the configured checkpoint location so that the query can deterministically reproc‐ ess the exact range if needed.
Spark Streaming under the hood
The loop continues until the query is terminated which can be for one of the following reasons:
A failure has occurred in the query (either a processing error or a failure in the cluster).
The query is explicitly stopped using streamingQuery.stop().
If the trigger is set to
Once, then the query will stop on its own after executing a single micro-batch containing all the available data.
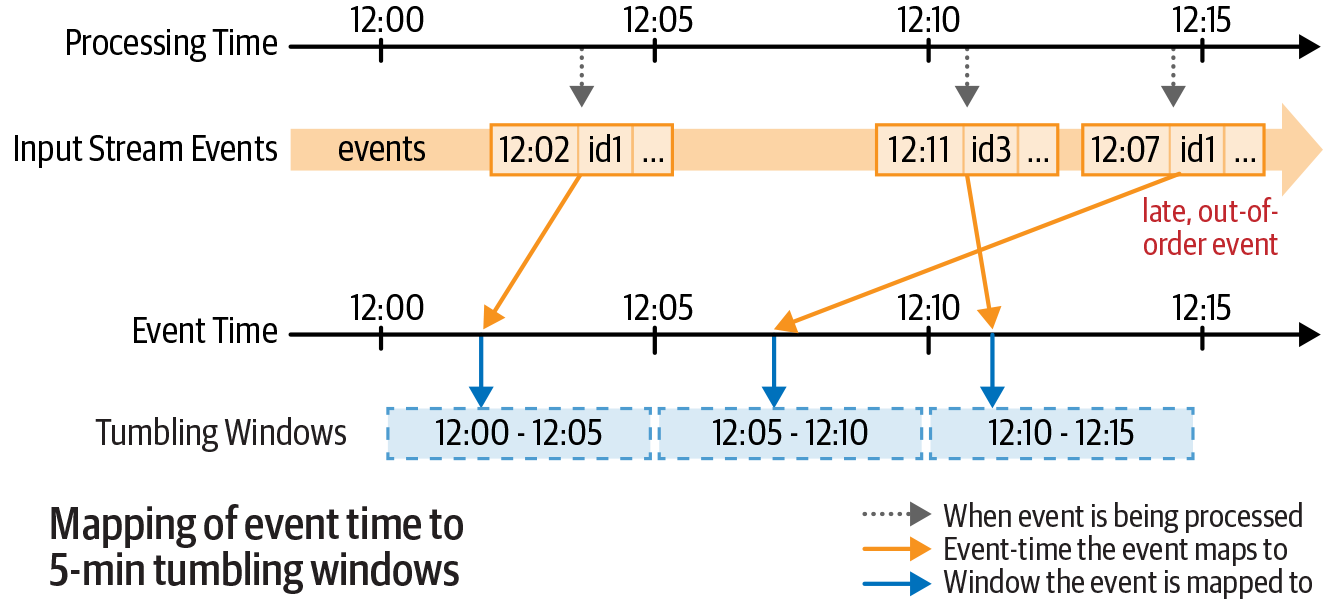
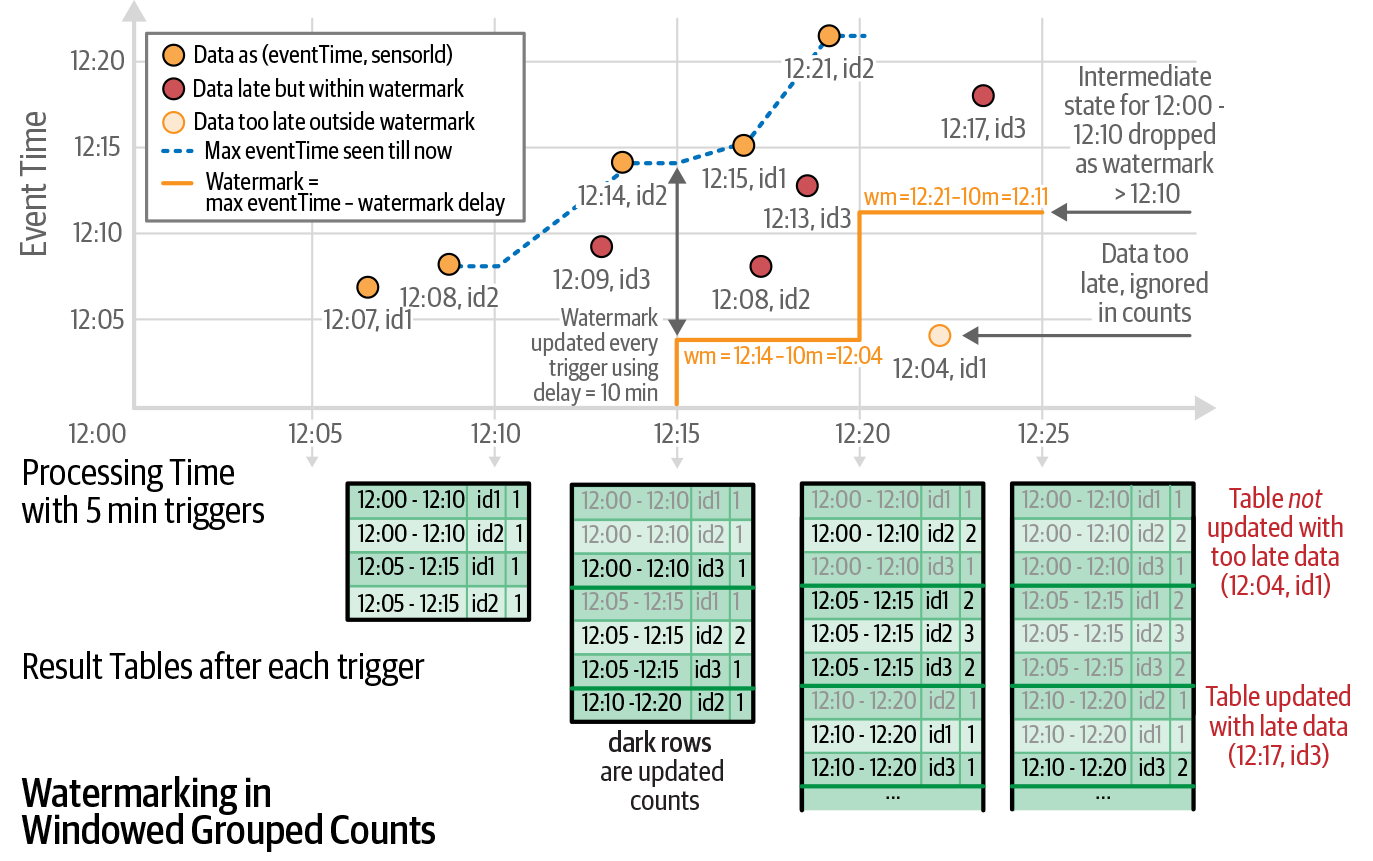
Mapping of event time to tumbling windows
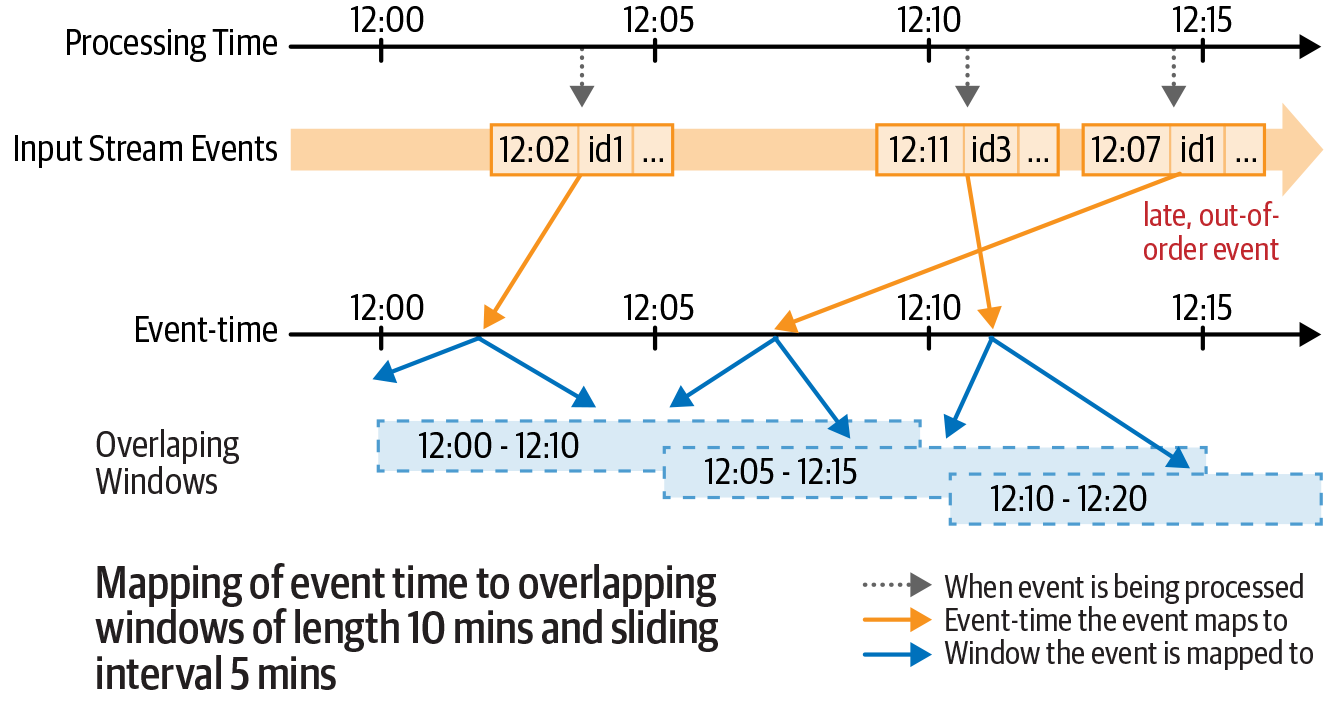
Mapping of event time to multiple overlapping windows
Updated counts in the result table after each five-minute trigger
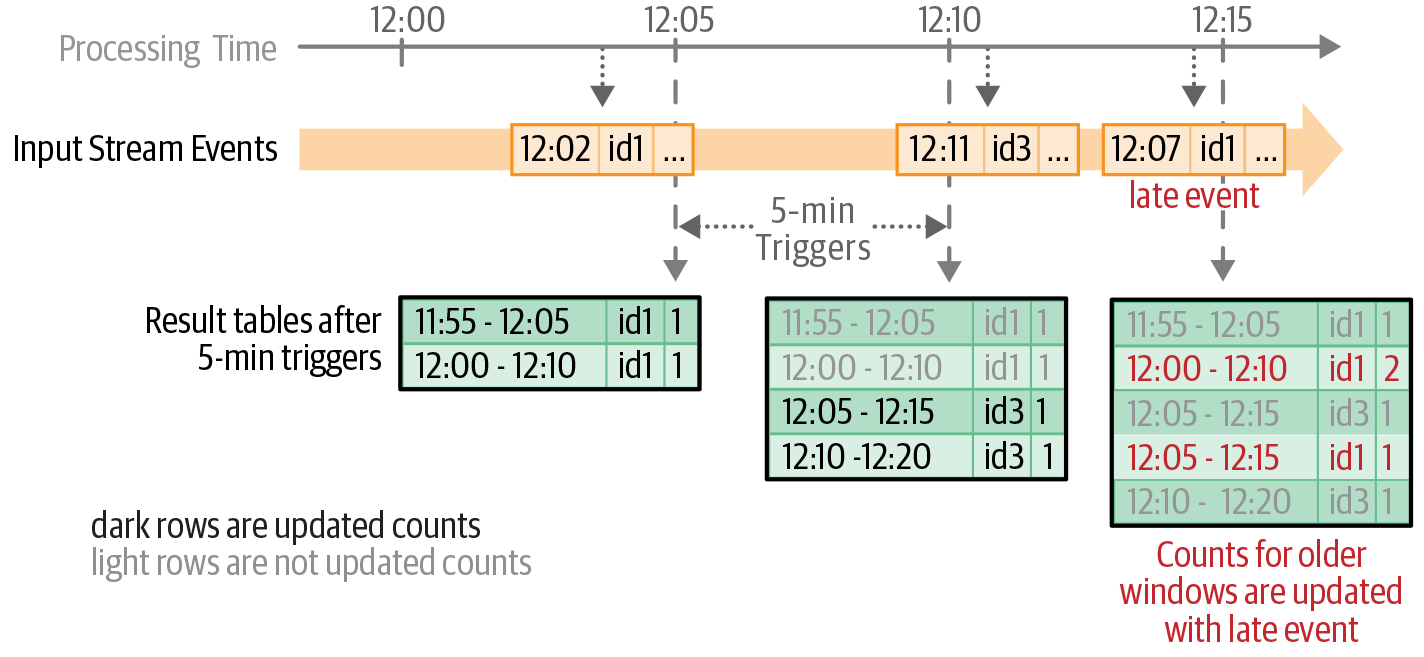
Using watermarks
A watermark is defined as a moving threshold in event time that trails behind the maximum event time seen by the query in the processed data. The trailing gap, known as the watermark delay, defines how long the engine will wait for late data to arrive.
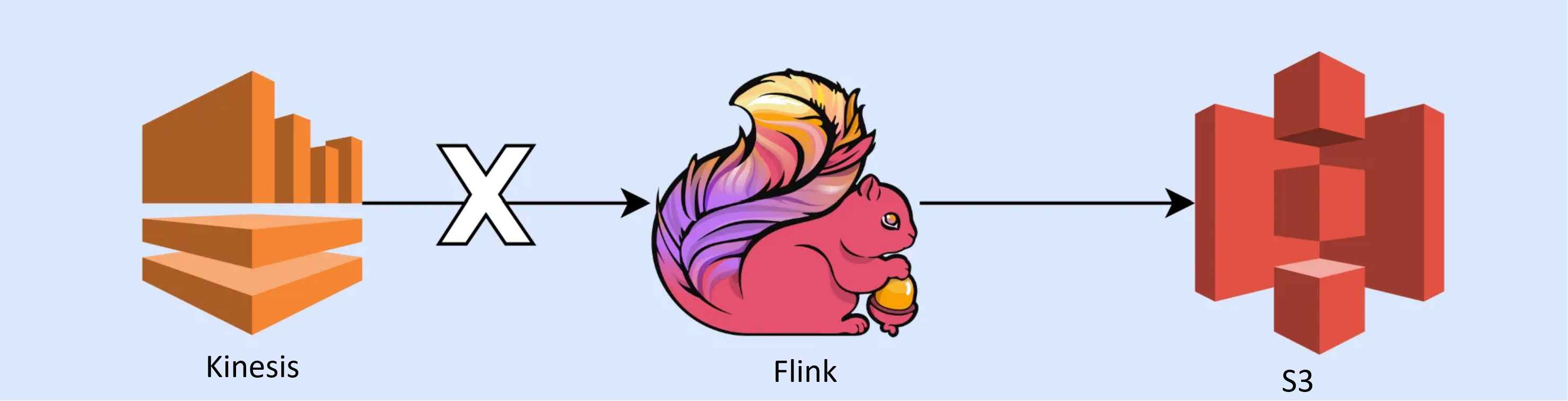
AWS Kinesis

- Similar to Apache Kafka
- Abstracts away much of the configuration details
- Costs based on usage
Read more comparisons here.
Real-world example
Lyft’s journey with Flink and Kinesis
Production failure
But one day the delay in processing spiked
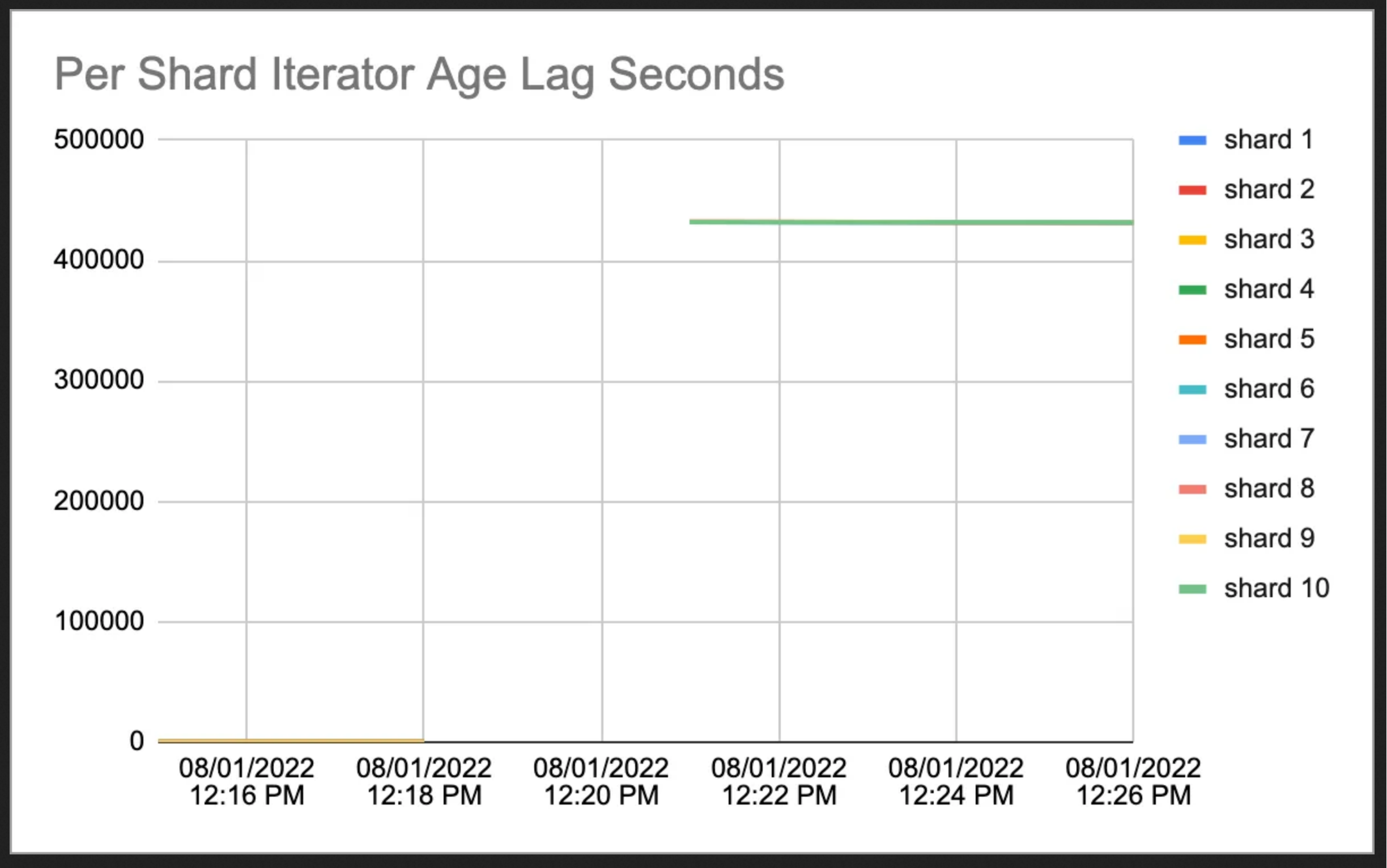
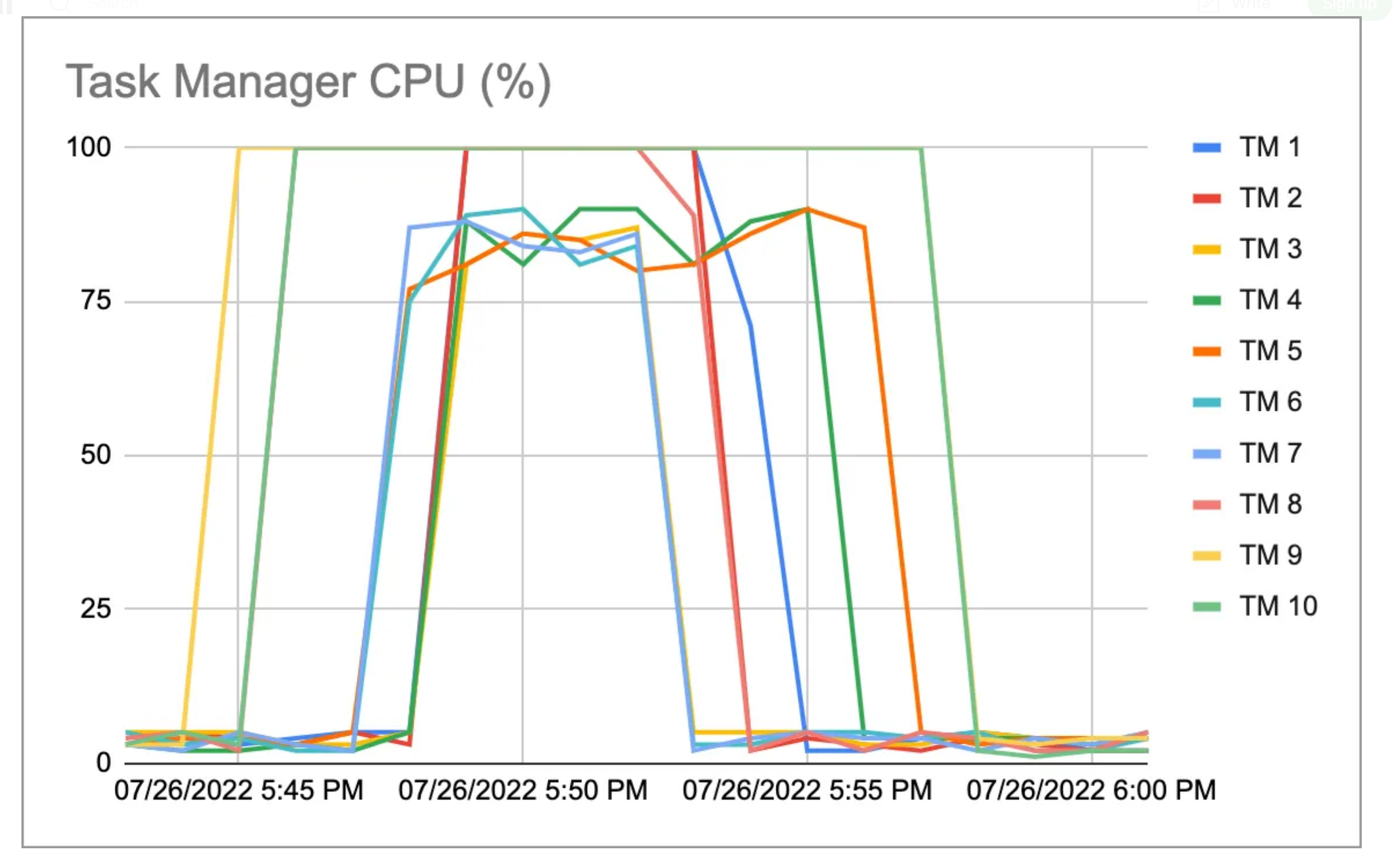
How was the streaming data getting processed?
- Async processing made things efficient but also exposed a vulnerability
- What if the processing fails or gets delayed relative to other shards?
- Mechanisms to keep the global timestamp in sync caused issues
- Timestamp got shifted backward - “time travel”
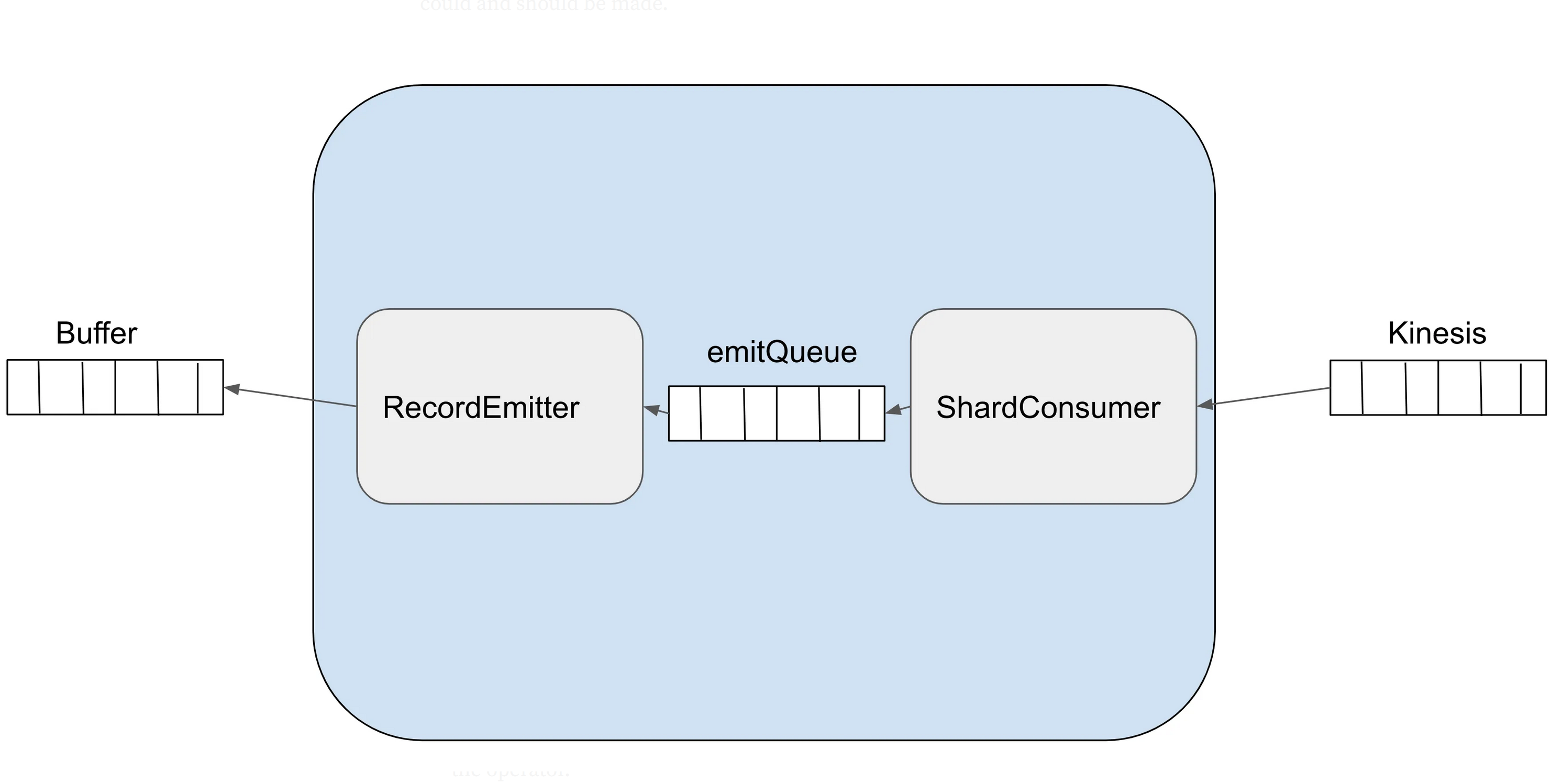
Shards competing for resources causing timestamp issues
