Lecture 8
SparkNLP and Project Setup
collect CAUTION

Spark UI - Executors
UDF Speed Comparison
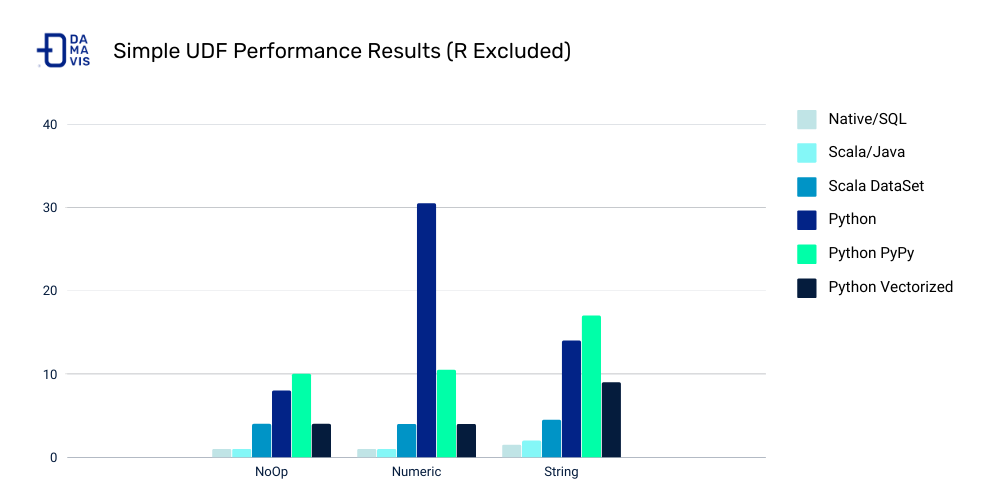
Costs:
- Serialization/deserialization (think pickle files)
- Data movement between JVM and Python
- Less Spark optimization possible
Other ways to make your Spark jobs faster source:
- Cache/persist your data into memory
- Using Spark DataFrames over Spark RDDs
- Using Spark SQL functions before jumping into UDFs
- Save to serialized data formats like Parquet
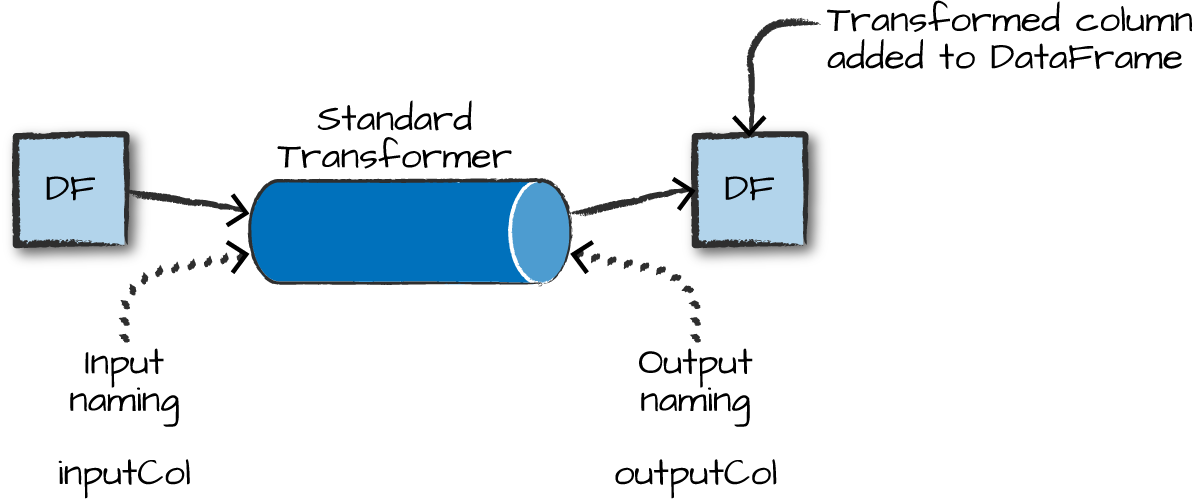
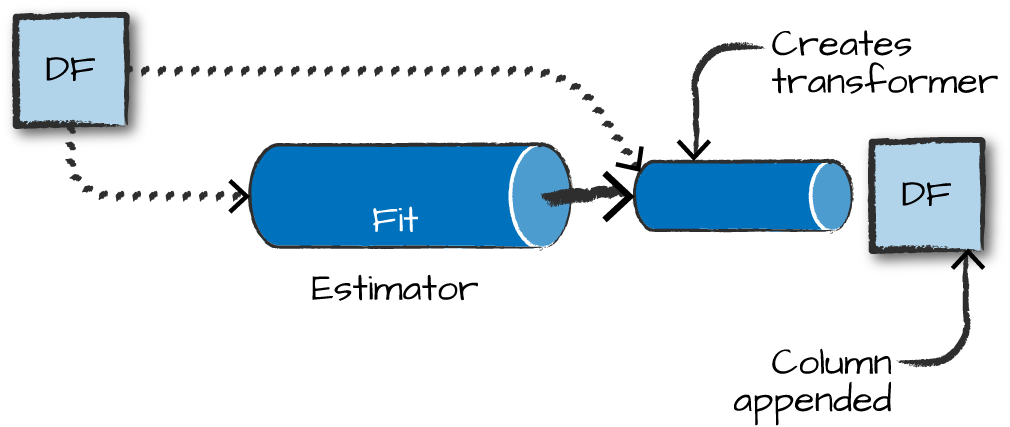
Transformers
Transformers take DataFrames as input, and return a new DataFrame as output. Transformers do not learn any parameters from the data, they simply apply rule-based transformations to either prepare data for model training or generate predictions using a trained model.
Transformers are run using the .transform() method
Estimators
Estimators learn (or “fit”) parameters from your DataFrame via the .fit() method, and return a model which is a Transformer
Application of Sentiment Analysis in PySpark
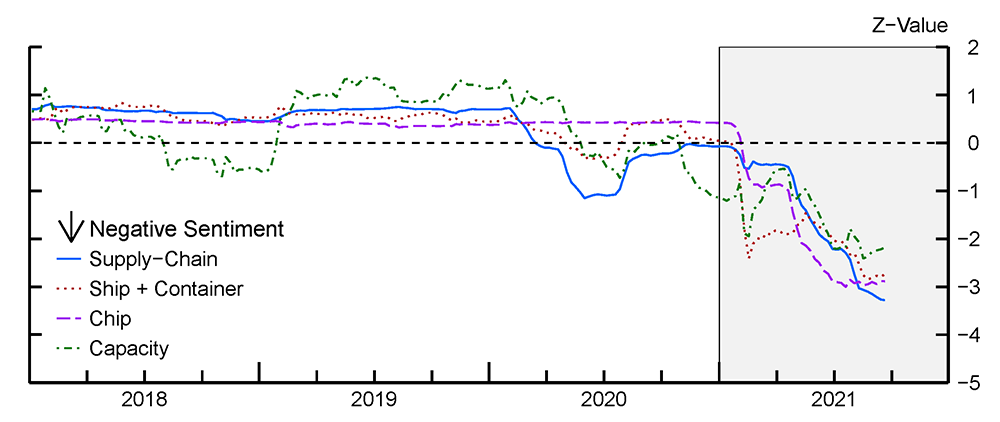
Data: S&P company earnings calls - 10s of millions of text statements
Method: proximity-based sentiment analysis
Tech: PySpark, Python UDFs, lots of list comprehensions!
Outcome: Time series trends of company concerns about supply chain related issues
JonSnowLabs Spark NLP Package
Why use UDFs, run proximity-based sentiment? Let’s use more advanced natural language processing packages!
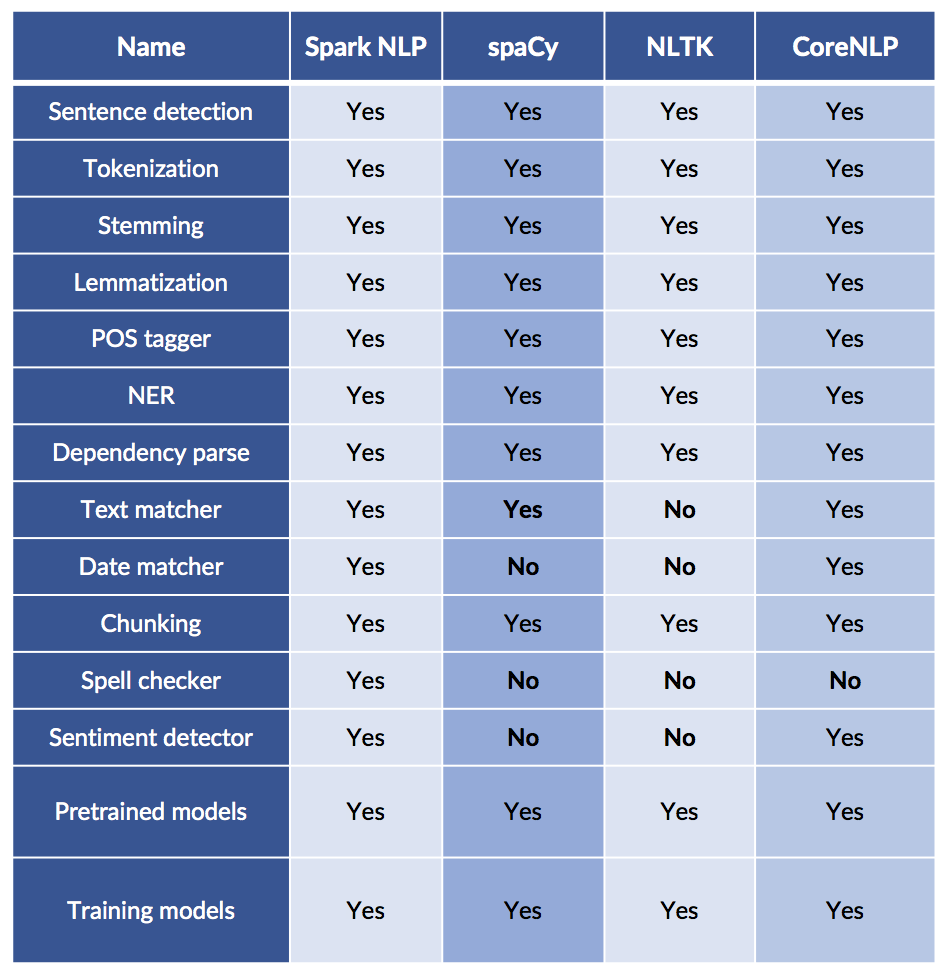
Which libraries have the most features?

Comparing NLP Packages
Just because it is scalable does not mean it lacks features!
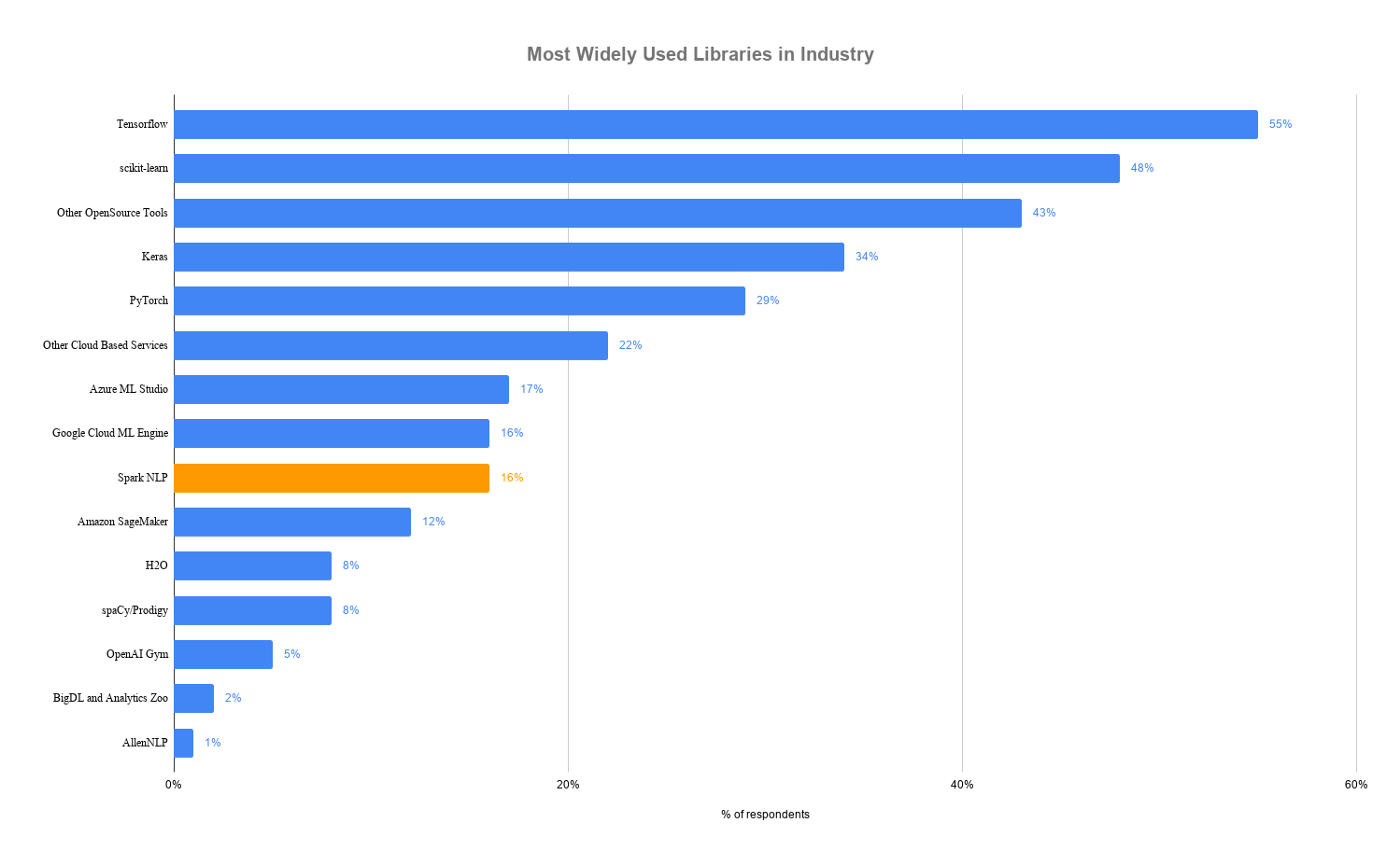
Most Popular AI/ML Packages
Spark NLP
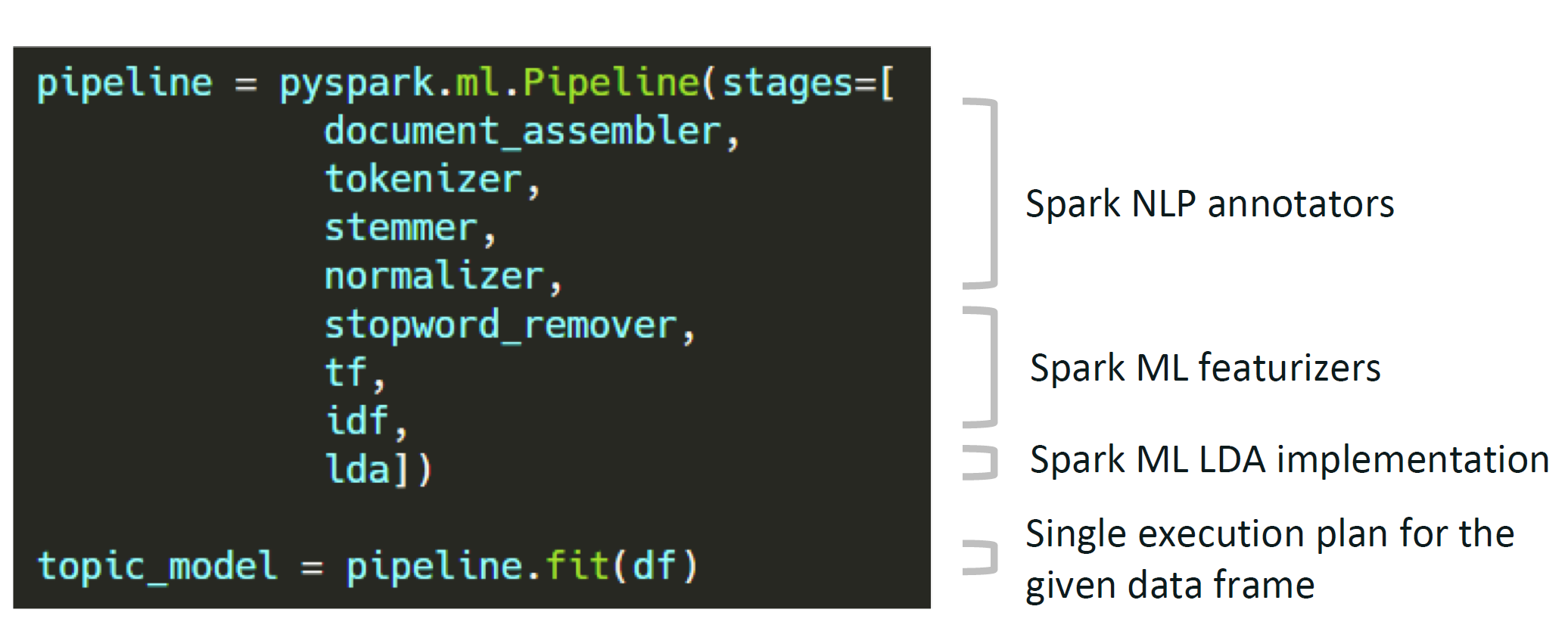
Reusing the Spark ML Pipeline
Unified NLP & ML pipelines
End-to-end execution planning
Serializable
Distributable
Reusing NLP Functionality
TF-IDF calculation
String distance calculation
Stop word removal
Topic modeling
Distributed ML algorithms

Spark NLP Sentiment Example
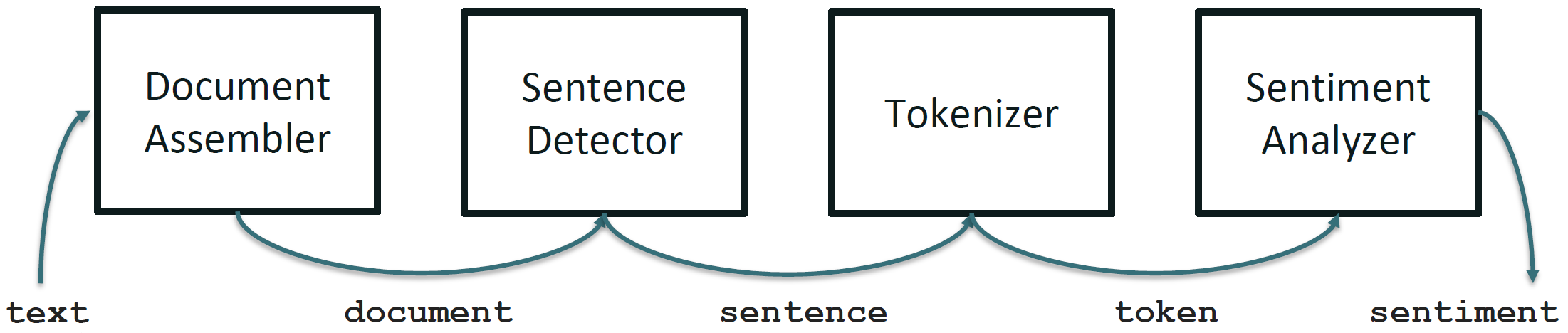
Spark NLP Pipeline Example