Lecture 7
Spark UDFs and Project Introduction
Connected and extensible
collect CAUTION

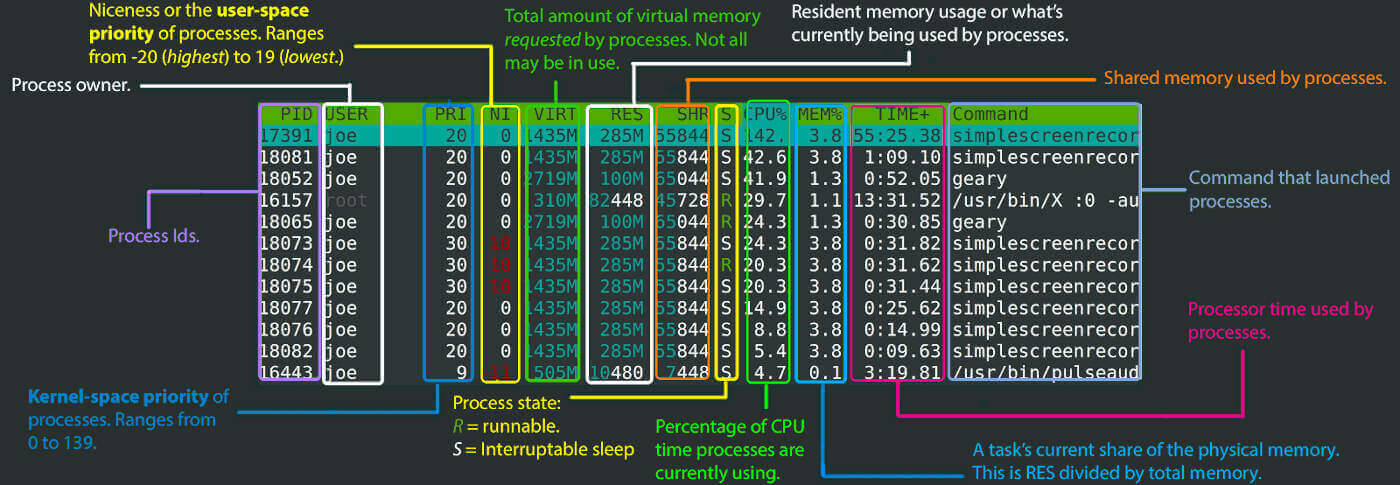
Review of htop
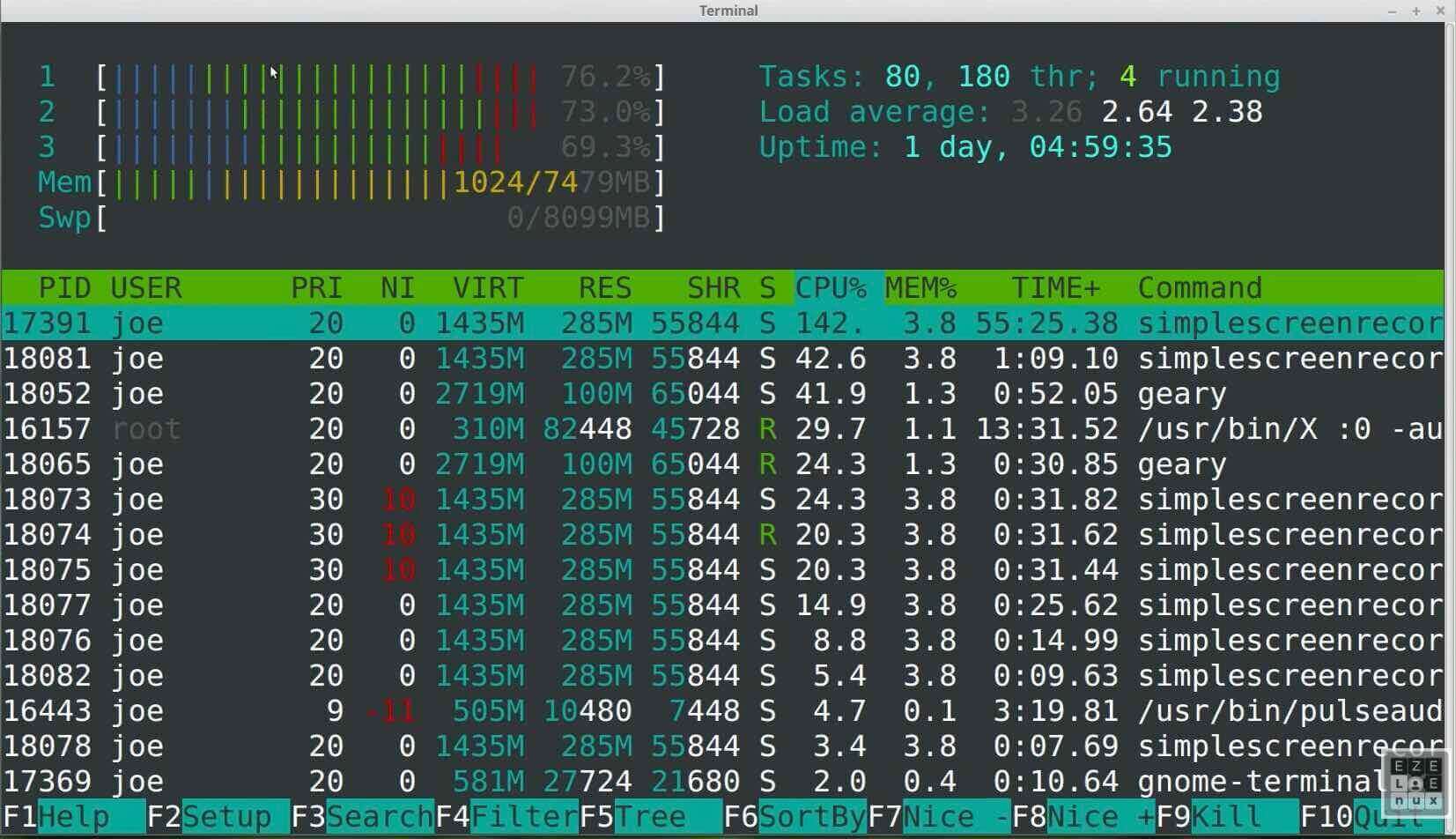
htop top section explanation

htop bottom section explanation
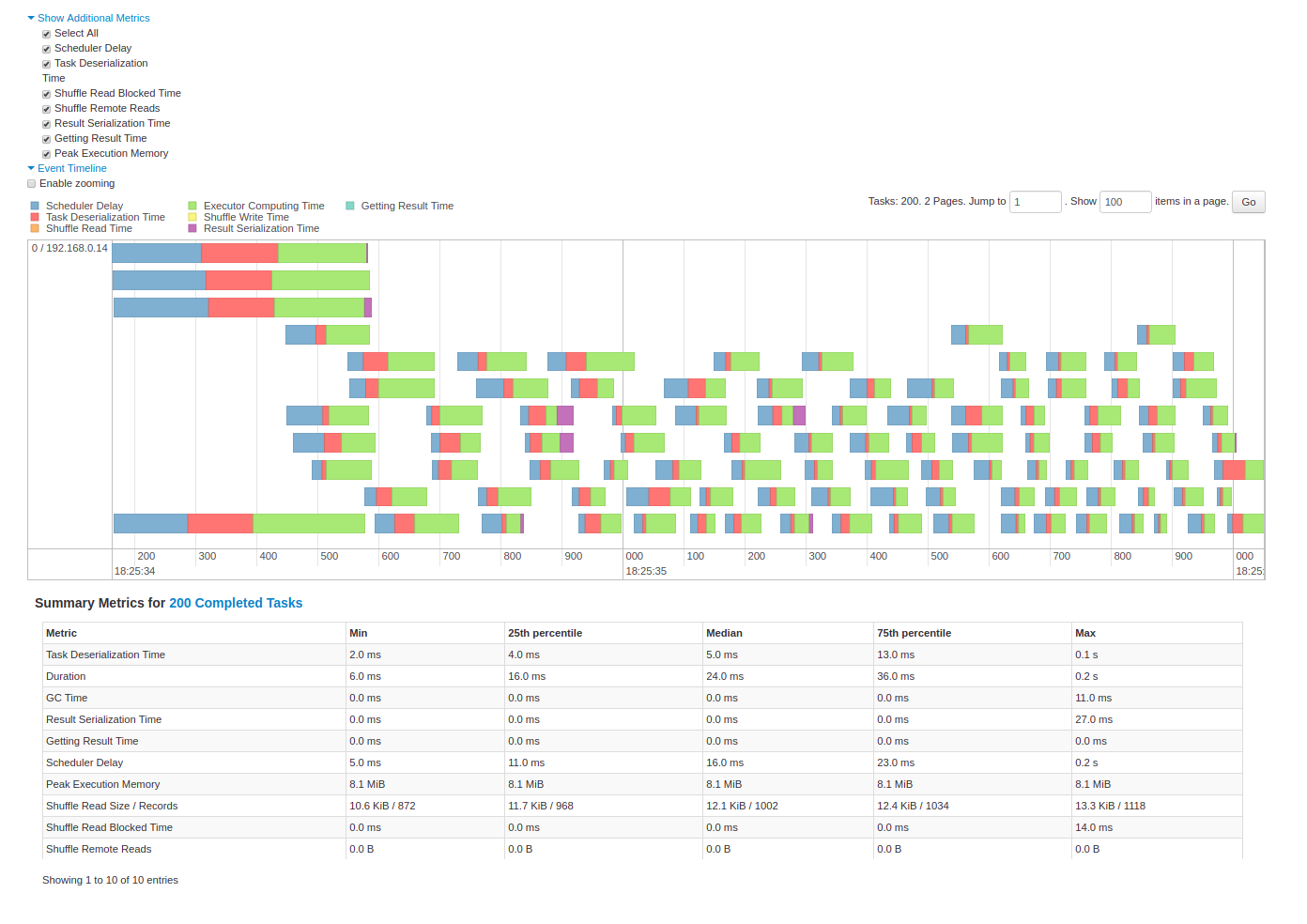
Spark UI - Event timeline
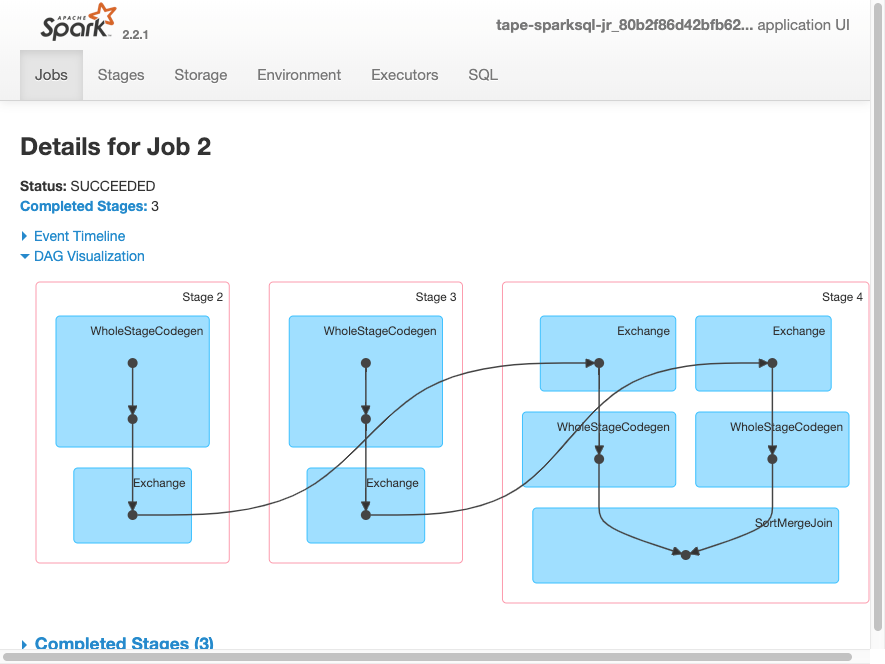
Spark UI - DAG
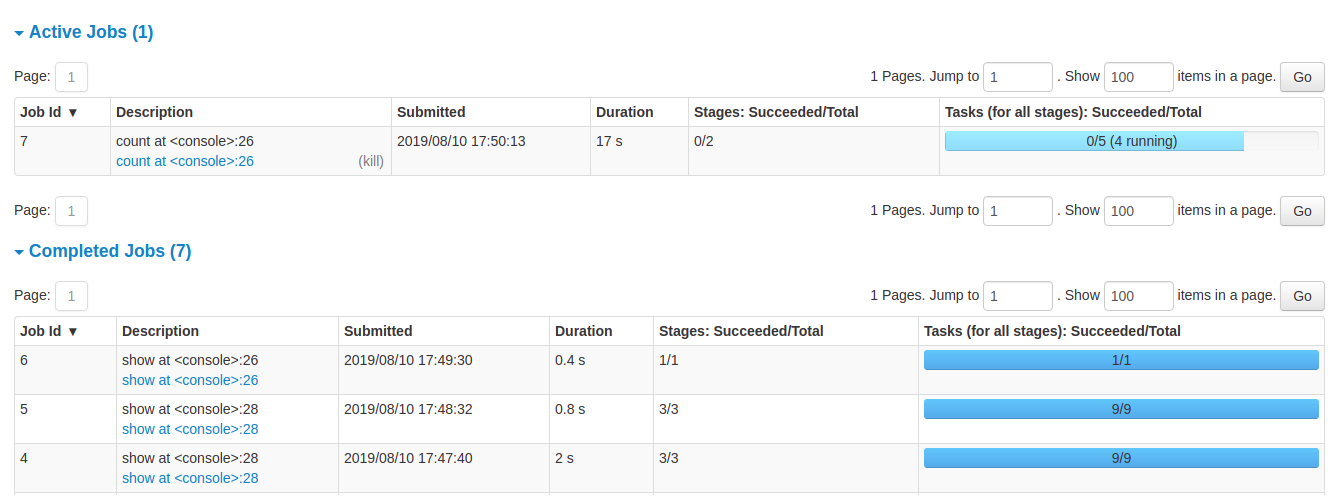
Spark UI - Job History
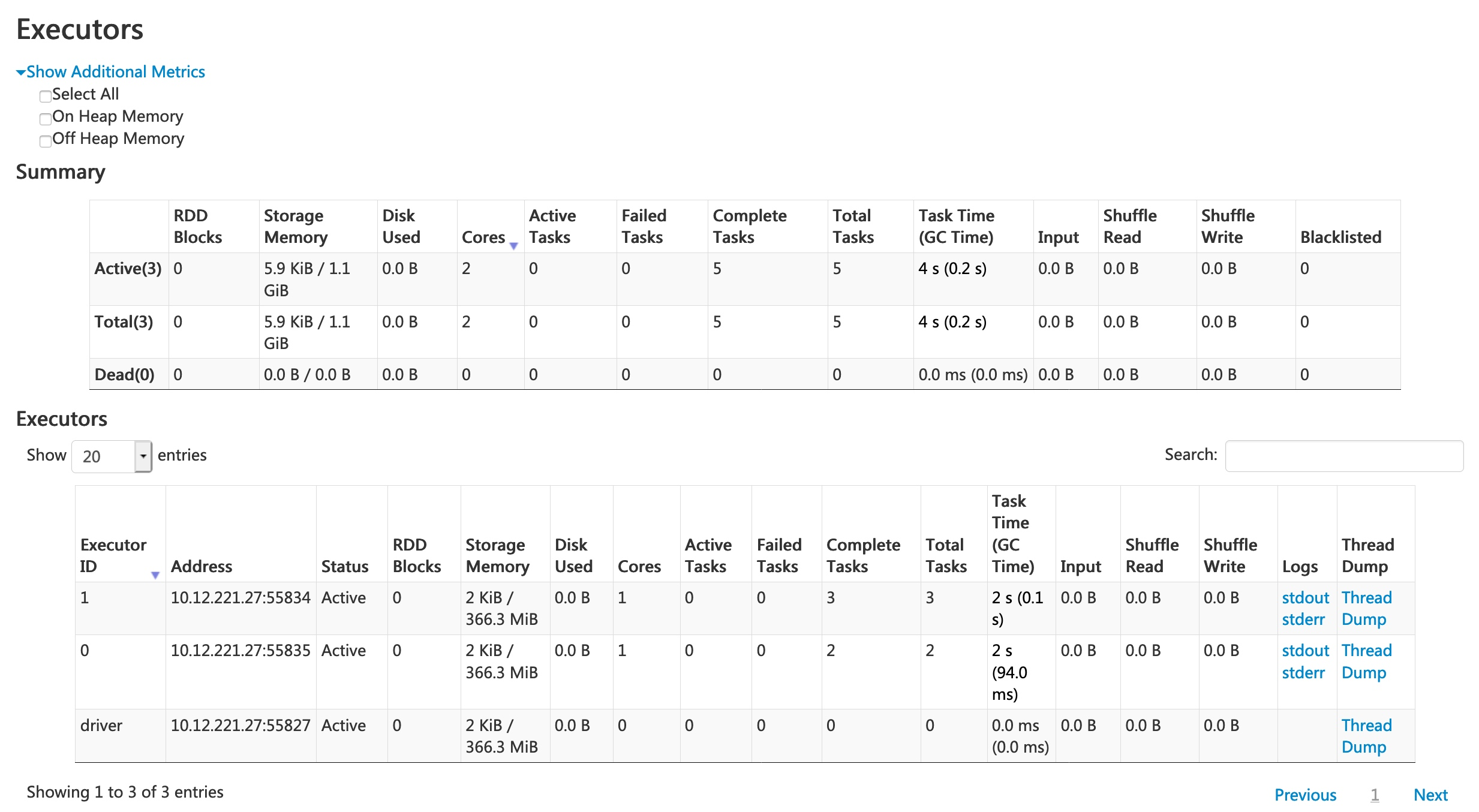
Spark UI - Executors
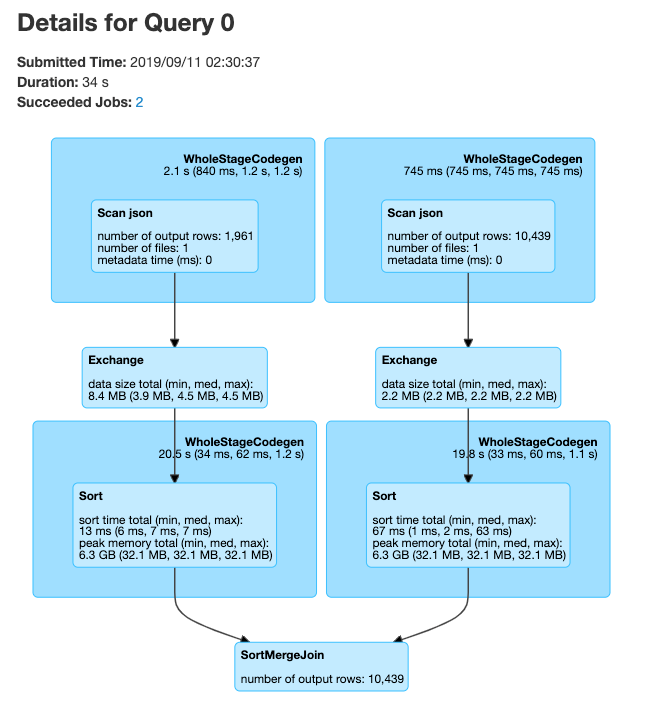
Spark UI - SQL
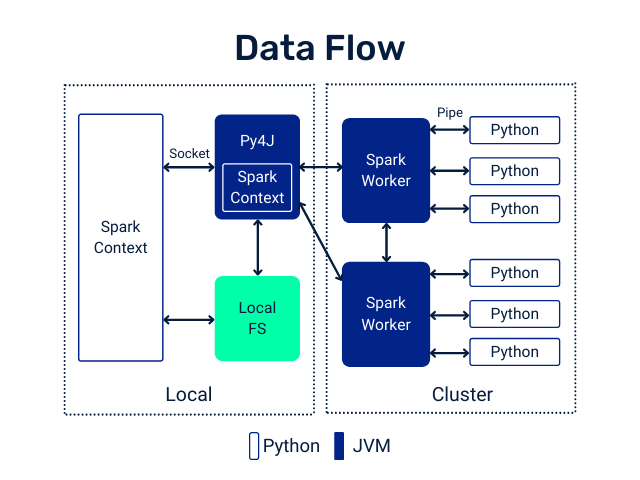
UDF Workflow
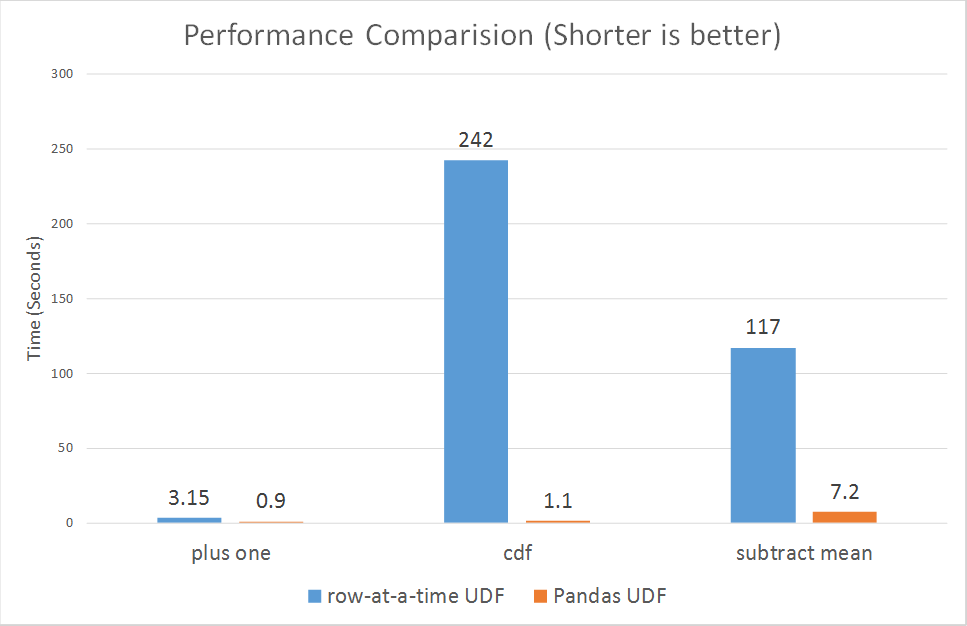
UDF Speed Comparison
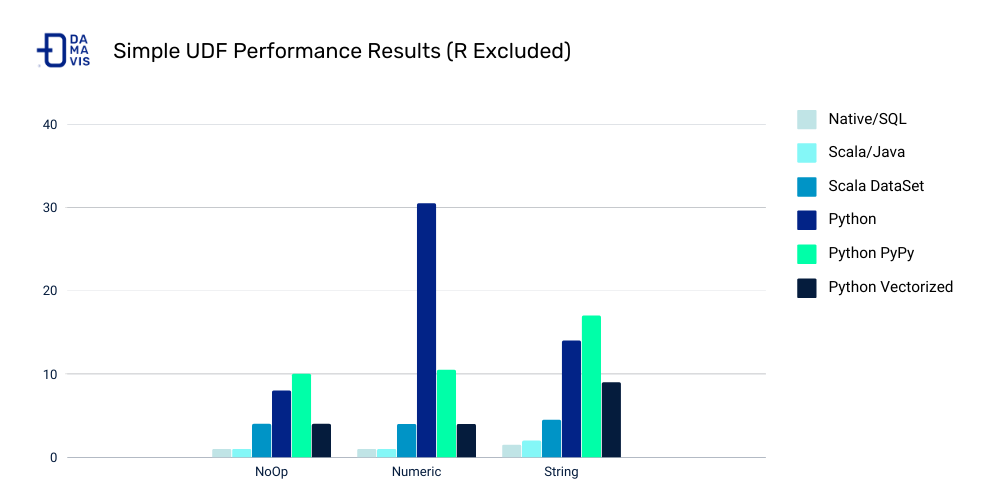
Costs:
- Serialization/deserialization (think pickle files)
- Data movement between JVM and Python
- Less Spark optimization possible
Other ways to make your Spark jobs faster source:
- Cache/persist your data into memory
- Using Spark DataFrames over Spark RDDs
- Using Spark SQL functions before jumping into UDFs
- Save to serialized data formats like Parquet
Comparison of Scalar and Grouped Map Pandas UDFs
Input of the user-defined function:
- Scalar: pandas.Series
- Grouped map: pandas.DataFrame
Output of the user-defined function:
- Scalar: pandas.Series
- Grouped map: pandas.DataFrame
Grouping semantics:
- Scalar: no grouping semantics
- Grouped map: defined by “groupby” clause
Output size:
- Scalar: same as input size
- Grouped map: any size
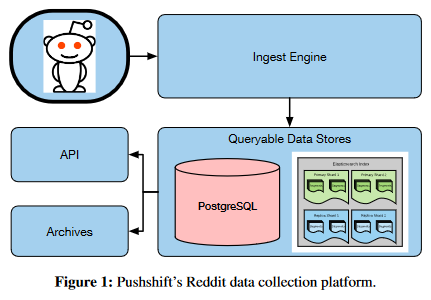
Reddit Data!

Reddit Background
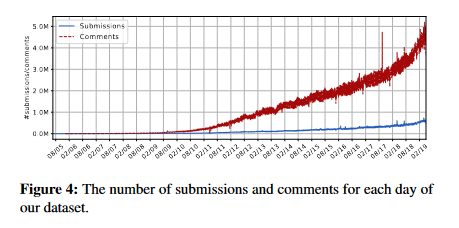
Comparison of social data infrastructure

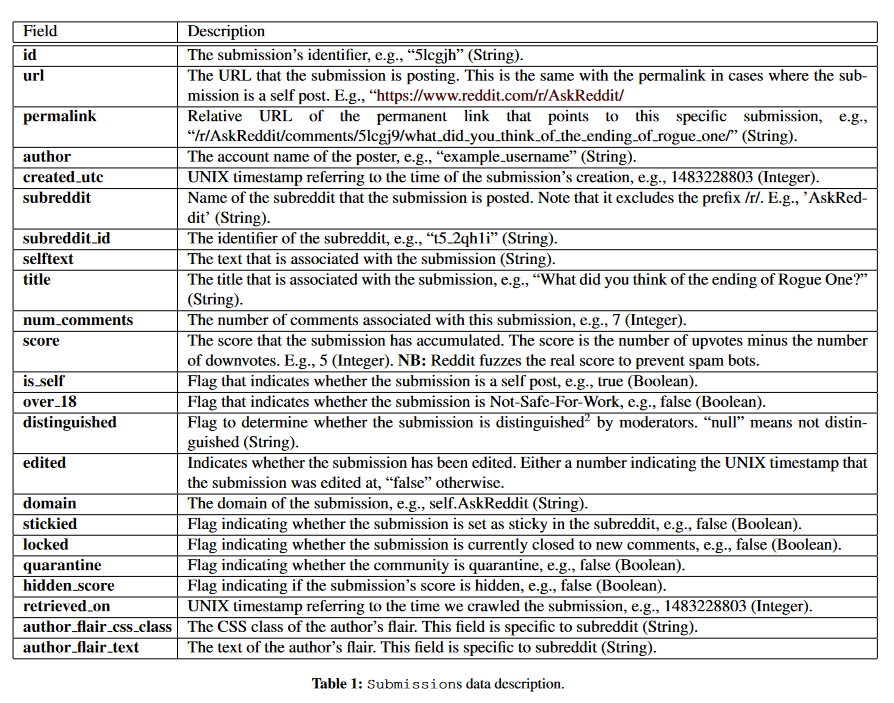
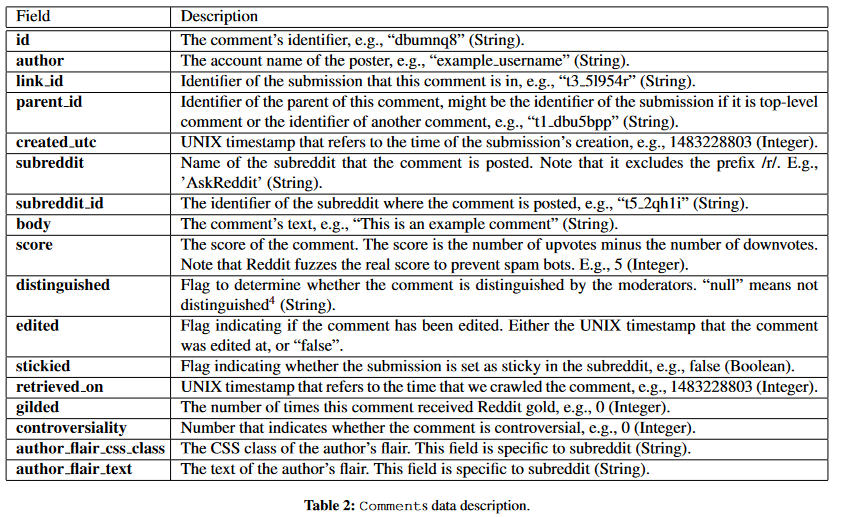
Data Dictionary