Lecture 5
File types, file systems, and working with large tabular data on a single node
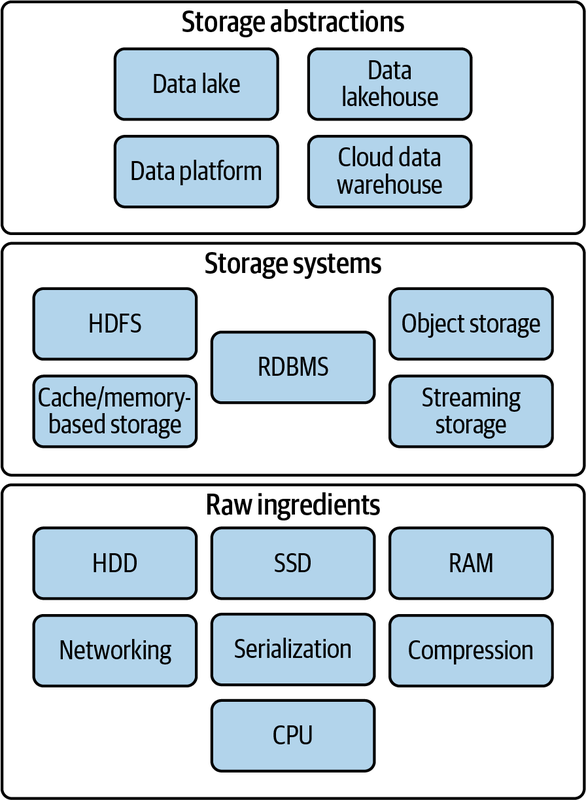
Raw ingredients of storage systems
- Disk drives (magnetic HDDs or SSDs)
- RAM
- Networking and CPU
- Serialization
- Compression
- Caching
Single machine vs. distributed storage

Single machine
- They are commonly used for storing operating system files, application files, and user data files.
- Filesystems are also used in databases to store data files, transaction logs, and backups.
Distributed storage
- A distributed filesystem is a type of filesystem that spans multiple computers.
- It provides a unified view of files across all the computers in the system.
- Have existed before cloud
Object stores
The term object storage is somewhat confusing because object has several meanings in computer science. In this context, we’re talking about a specialized file-like construct. It could be any type of file: TXT, CSV, JSON, images, videos, audio, or pretty much any type of file.


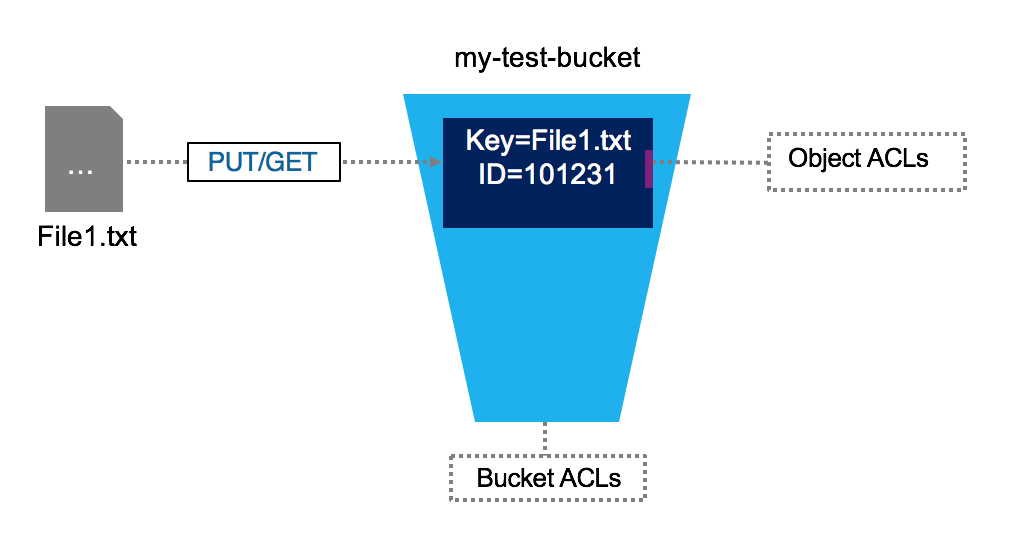
- Contains objects of all shapes and sizes.
- Every object gets a unique identifier
- Objects are immutable; cannot be modifier in place (unlike local FS)
- Distributed by design
- Massively scalable REST API access
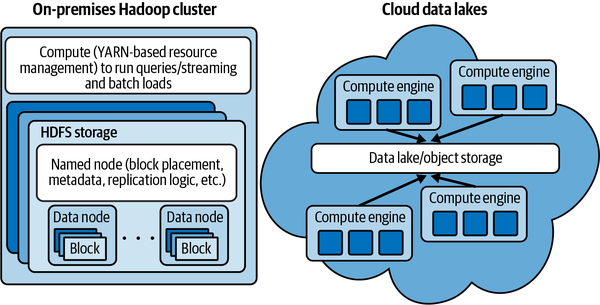
Before: Data locality (for Hadoop)
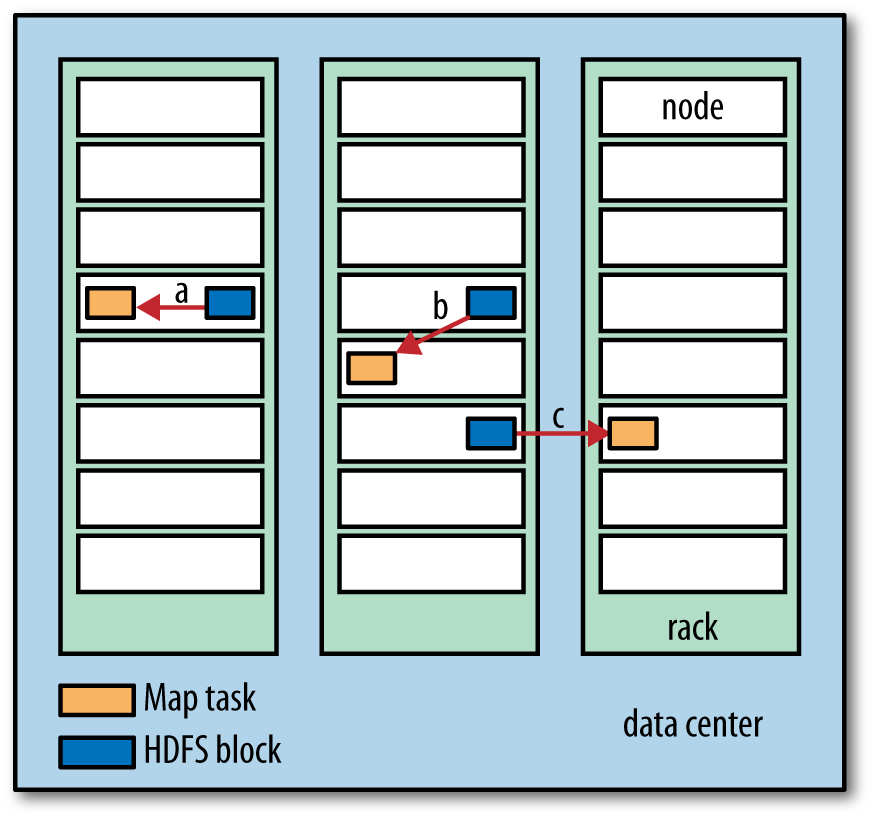
Today: de-coupling storage from compute
Plain Text (CSV, TDF, FWF)

- Pay attention to encodings!
- Lines end in linefeed, carriage-return, or both together depending on the OS that generated
- Typically, a single line of text contains a single record
Binary files
Traditional row-store
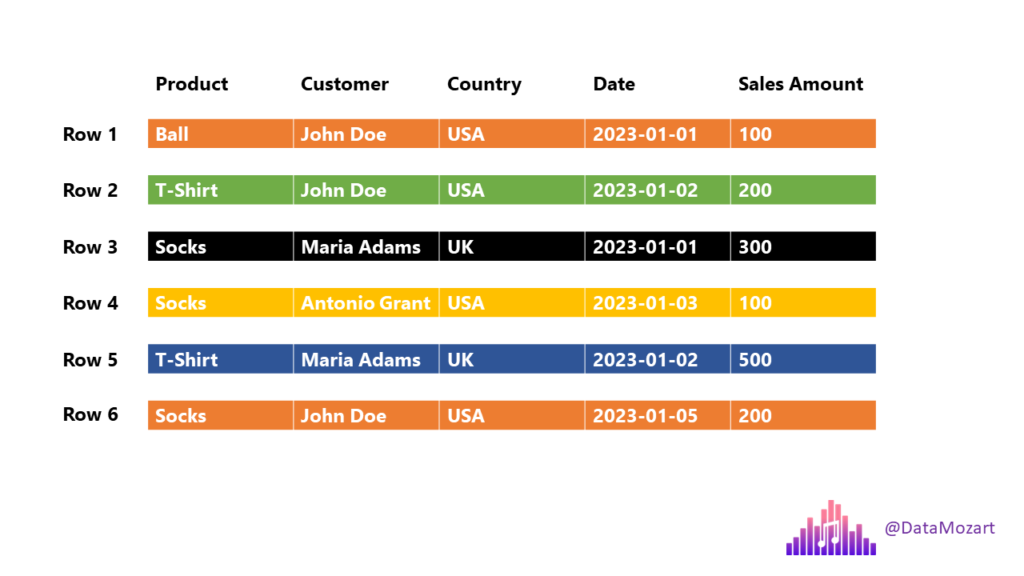
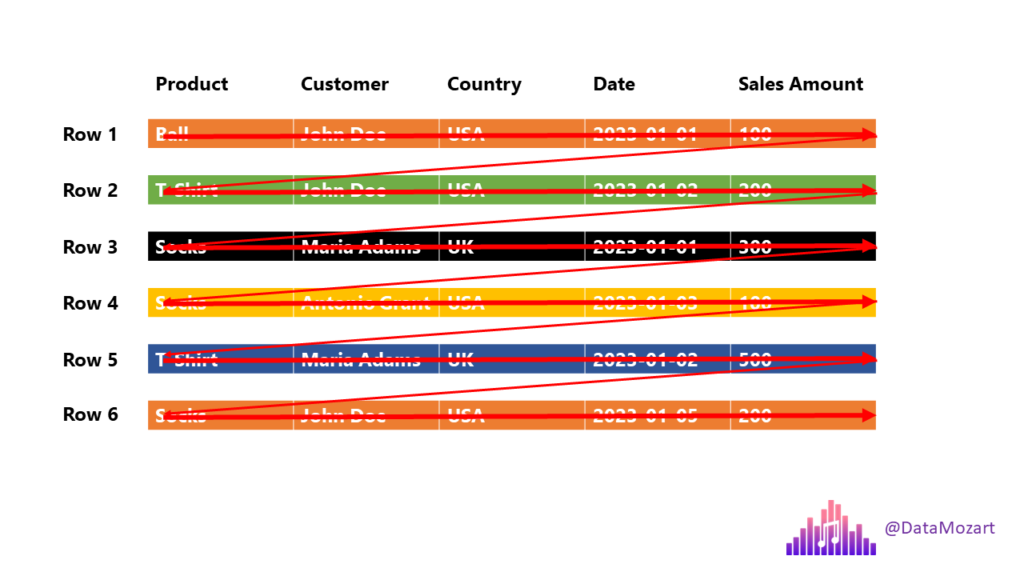
Say you wanted to answer the question “How many balls did we sell?, the engine must scan each and every row until the end!
Column-store
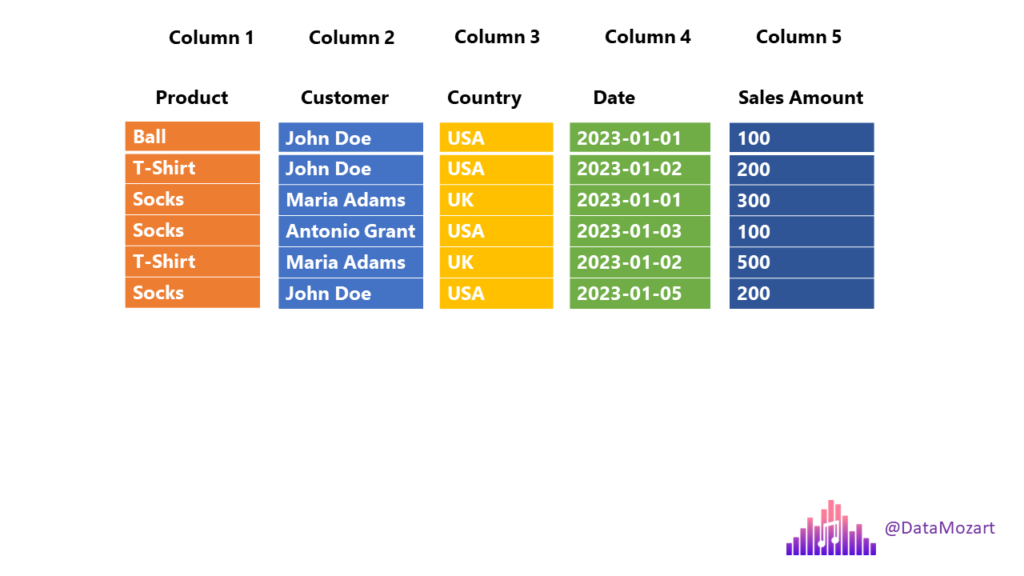
Row groups
Data is stored in row groups!
Only the required fields
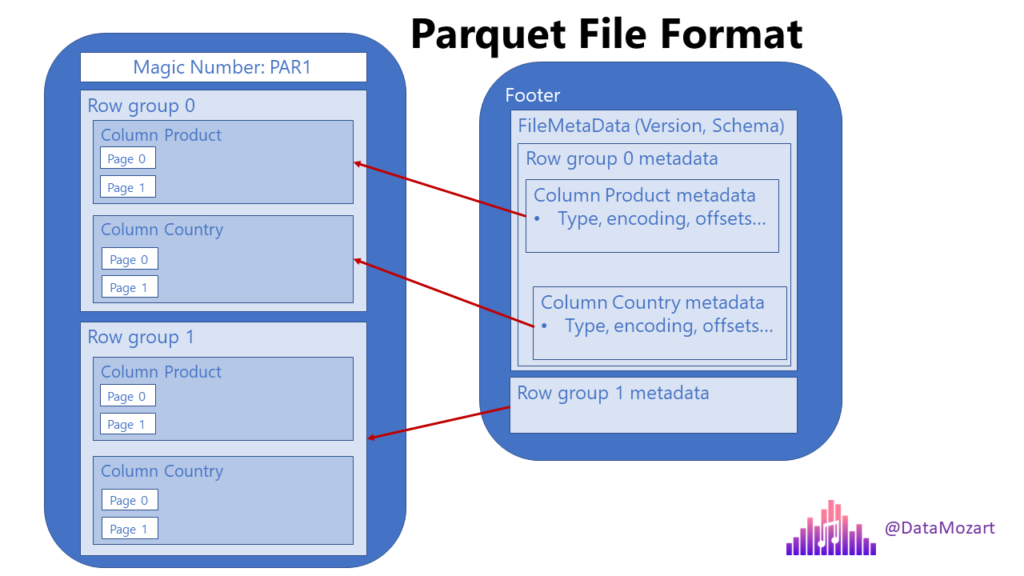
Metadata, compression, and dictionary encoding

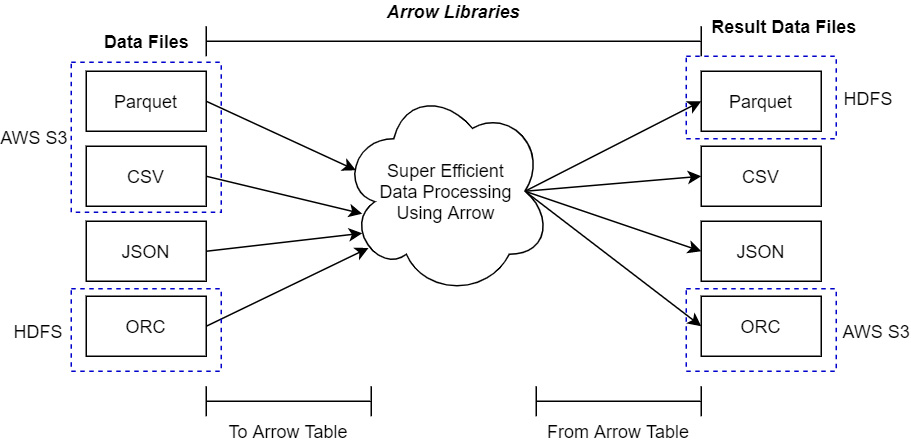
Before Arrow
![]()
After Arrow
![]()
Arrow Compatibility
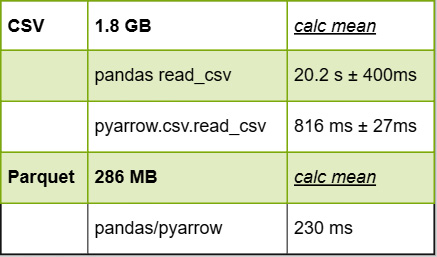
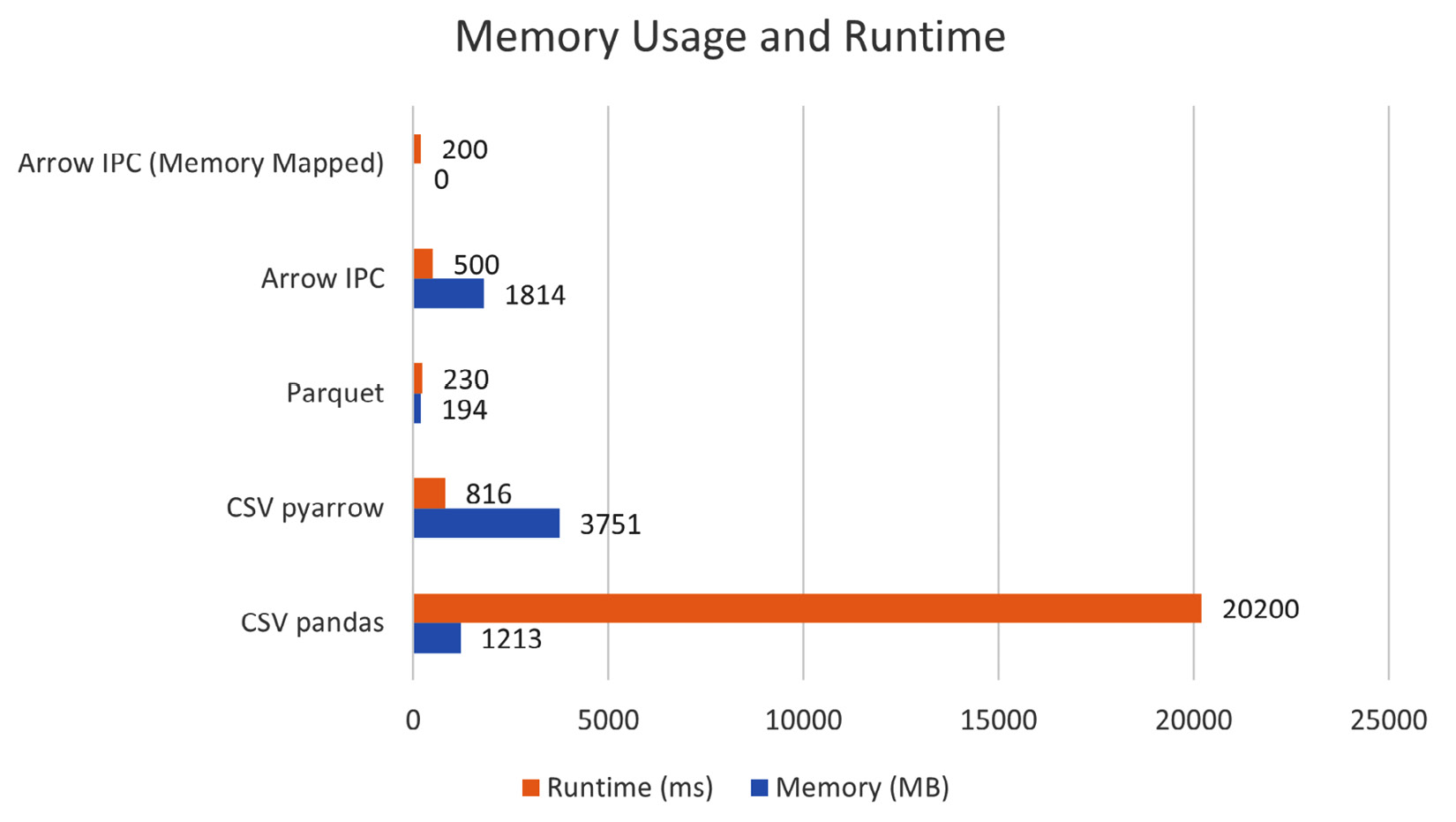
Arrow Performance
Polars

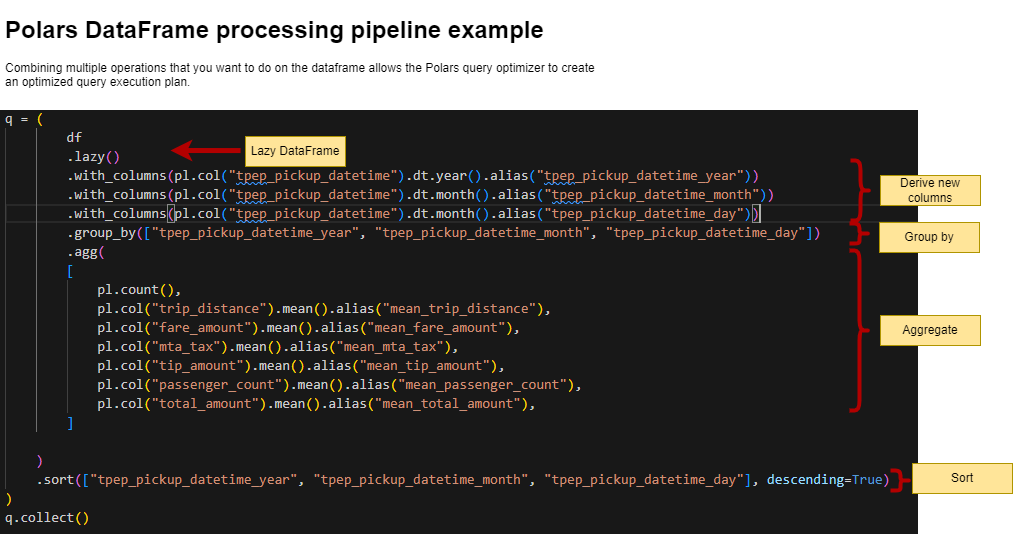
A Polars DataFrame processing pipeline example
Here is an example that we will run as part of the lab in a little bit.
Think how you would code this same pipeline in Pandas…
Polars pipeline
DuckDB - quick introduction
DuckDB is an in-process SQL OLAP database management system

Duck DB
How might you think about DuckDB - DIY Version
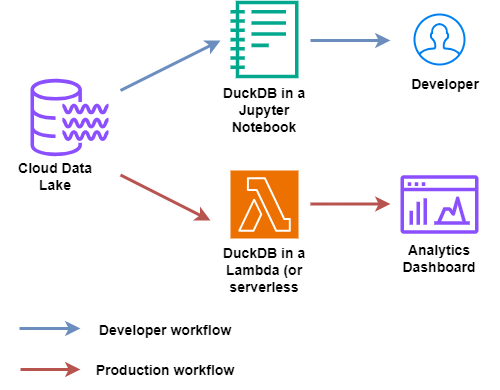
Datalake and DuckDB
Modern Data Stack in a Box with DuckDB: DuckDB, Meltano, Dbt, Apache Superset
How might you think about DuckDB - Fully-managed
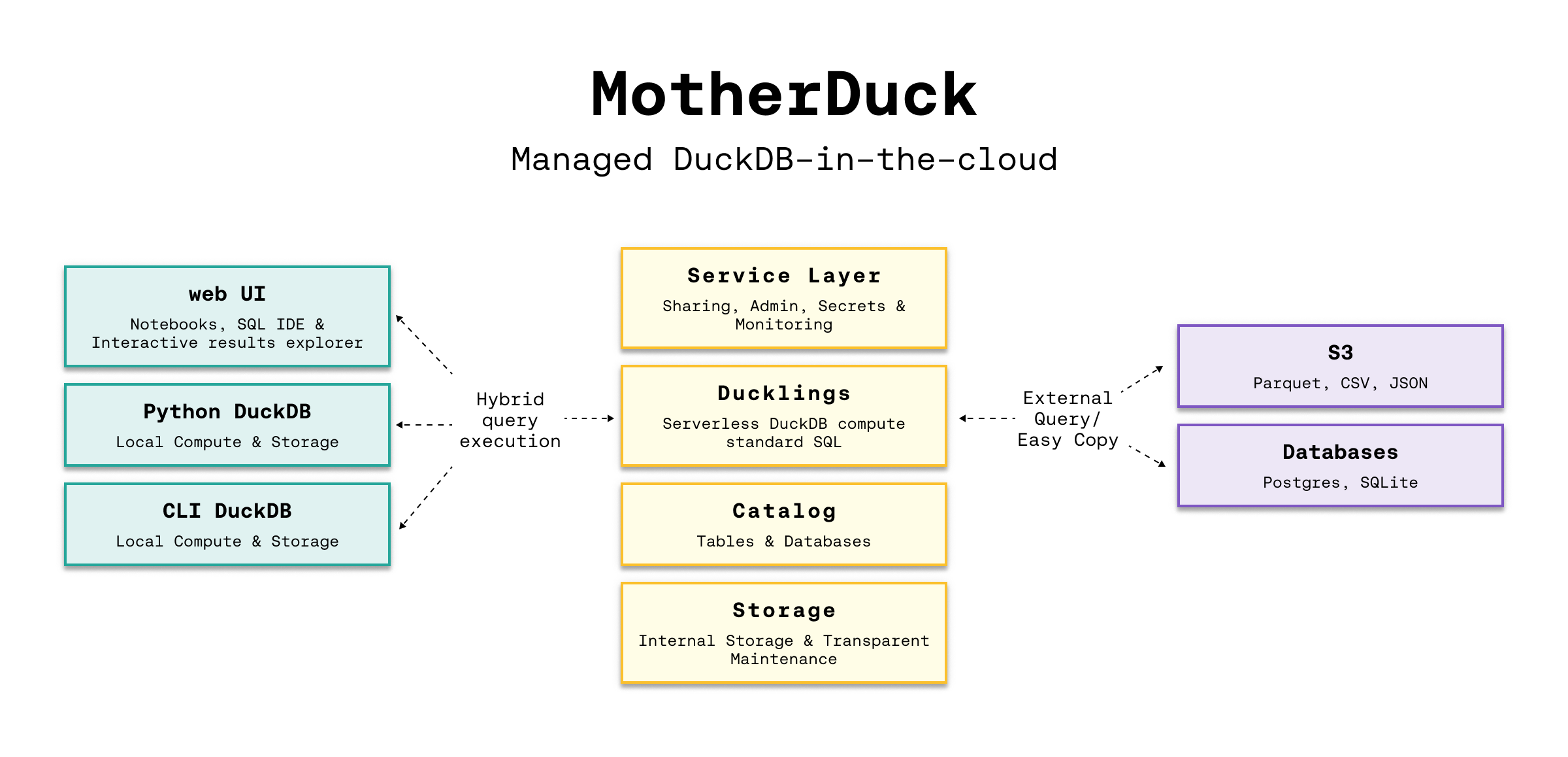
Seamlessly analyze data, whether it sits on your laptop, in the cloud or split between. Hybrid execution automatically plans each part of your query and determines where it’s best computed. If you use DuckDB with data lakes in s3, it’ll be much faster to run your analyses on MotherDuck.
Benchmarks and Comparisons
- This is a tricky topic, in general, you can make your choosen solution look better by focussing on metrics on which your choosen solution provides better results.
- Some links to explore further:
Reddit post: Benchmarking for DuckDB and Polars
TPC-H benchmarks for DuckDB: did not find anything on the duckdb.org, but this site has several DuckDB TPC-H benchmarks.