Lecture 1
Course overview, introduction to big data and the Cloud
Marck Vaisman
- AI & ML Cloud Architect and Data Scientist at Microsoft
- Teaching at GWU since 2015 (9 year) and Georgetown since 2016
- Co-Founder of DataCommunityDC
- R Fanatic
Fun Facts
- I love music and try to play music at the beginning of class, typically EDM. Other genres I love:
- Latin
- Bluegrass
- Chill
- I speak fluent Spanish, I grew up in Venezuela
- Love beer & bourbon
- Goofball
- Westie owner
- I can speak like Donald Duck

Amit Arora
- Principal Solutions Architect - AI/ML at AWS
- Adjunct Professor at Georgetown University
- Multiple patents in telecommunications and applications of ML in telecommunications
Fun Facts
- I am a self-published author https://blueberriesinmysalad.com/
- My book “Blueberries in my salad: my forever journey towards fitness & strength” is written as code in R and Markdown
- I love to read books about health and human performance, productivity, philosophy and Mathematics for ML. My reading list is online!

Anderson Monken
- Data Science Manager at Federal Reserve Board of Governors
- Team uses big data, web development, software development, machine learning, and AI
- Technology and cloud initiatives
- Research focus in international trade and economics
- Adjunct Professor since 2022
- DSAN Program Graduate
Fun Facts
- Amateur car mechanic on several old BMWs
- Can solve a Rubik’s Cube in under a minute
- Canoe’d over 200 miles in Canada

Abhijit Dasgupta
- Data Science Associate Director at AstraZeneca supporting Oncology R&D
- bioinformatics, biomarkers, clinical studies
- autoencoders, survival analysis, signal processing
- Adjunct Professor at Georgetown since 2020
- R and reproducible research evangelist
- Python is cool too!!
- Co-founder of Statistical Programming DC (with Marck Vaisman)
Fun Facts
- I’m a 4th degree black belt in Aikido,
- over 30 years experience providing flyer miles
- Exploring global whiskey, currently on Japan
- Active in community theater, mainly behind but sometimes on-stage.

Isfar Baset
- Earned my Bachelor’s in Computer Science from Grand Valley State University.
- Worked as a Data Analyst for a digital marketing firm (Shift Digital) prior to joining the DSAN program.
- Favorite places to visit around DC: Old Town Alexandria, The Wharf, and Georgetown Waterfront.
- I have a 6-month-old pet kitten named Cairo.
- I love to read books, paint, and watch movies/TV shows during my free time.

Dheeraj Oruganty
- Educational Background: Achieved a Bachelor’s Degree in Computer Science from Jawaharlal Nehru Institute of Technology in Hyderabad.
- Internship: Served as a Machine Learning Intern at Cluzters.ai, contributing to the development of machine vision models tailored for edge devices.
- Personal Interests: Finds joy participating in hikes, meeting new people and embarking on road trips.
- Interesting Tidbits: Explored 6 different countries in the past 90 days.
- Adventurous Journey: Undertook a remarkable 15-hour road trip on a motorcycle in India!

Lianghui Yi
- Undergraduate major in Information Engineering
- Co-founder of a SaaS company in China
- Currently a 1st-year student in DSAN

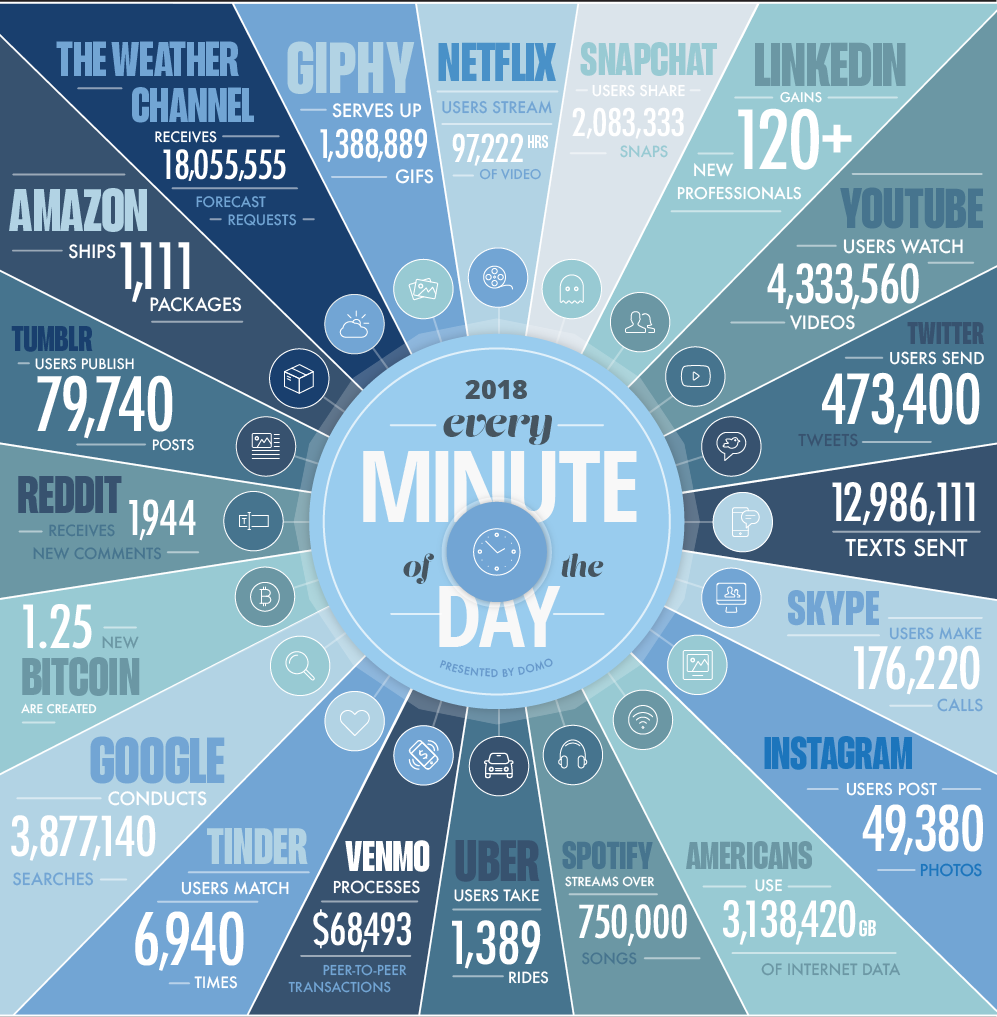
In one minute of time (2018)
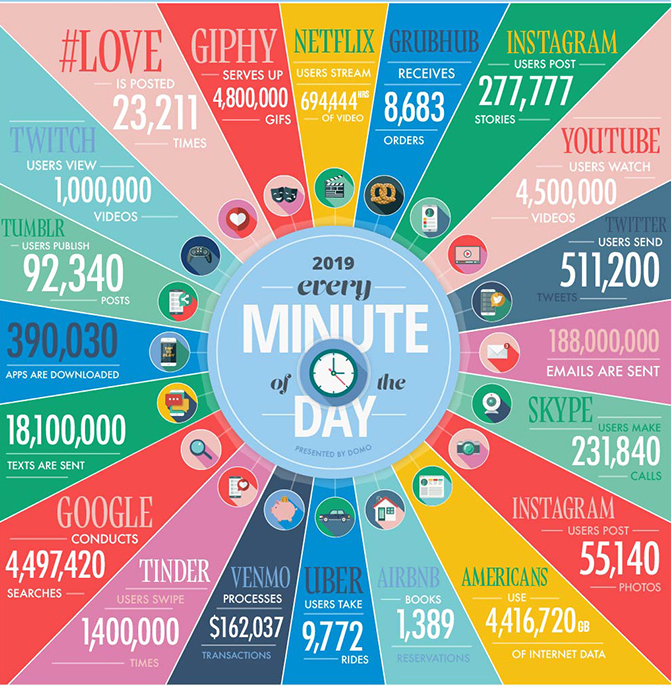
In one minute of time (2019)
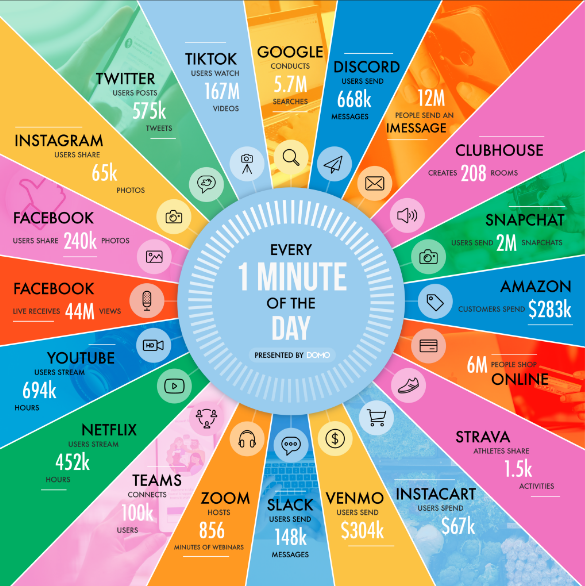
In one minute of time (2020)

In one minute of time (2021)
A lot of data is machine generated and hapenning online
We can record every:
- click
- ad impression
- billing event
- video interaction
- server request
- transaction
- network message
- fault
- and more…

Humans generate a substantial amount (everything is digital)!
- Tiktok
- Tweets
- Videos ()
- Yelp reviews
- Facebook posts
- Stack Overflow posts
- etc.

Health and scientific computing generate a lot too!
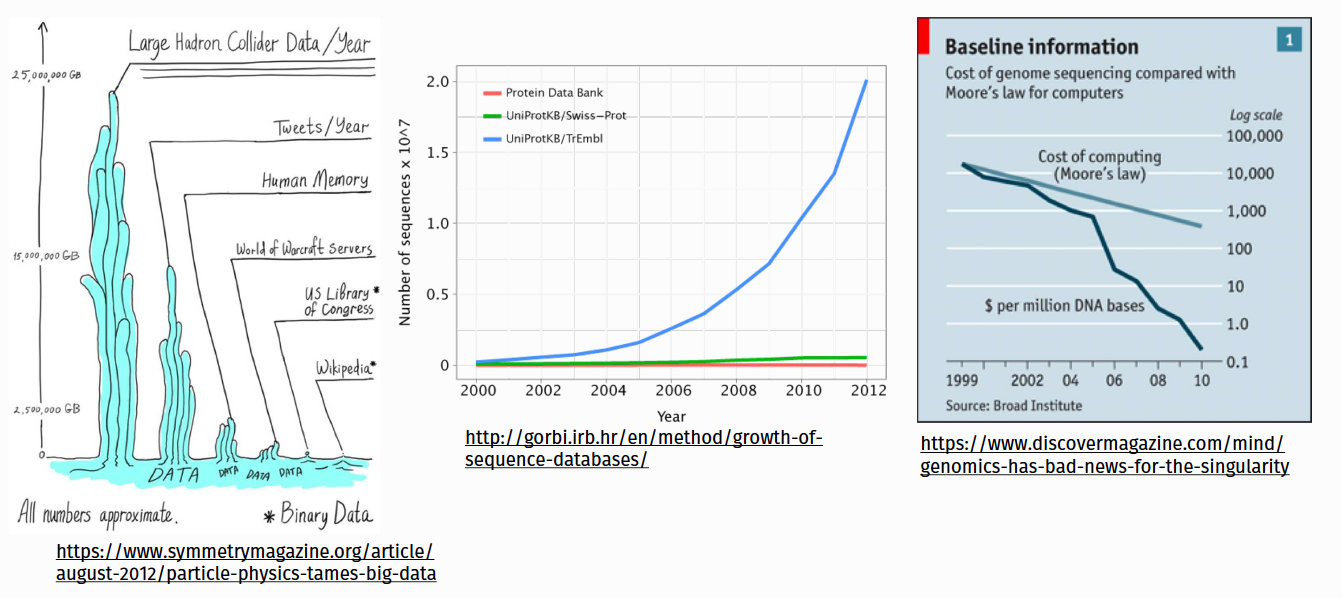
Data is growing exponentially and old ways don’t work

Most organizations don’t really have much data
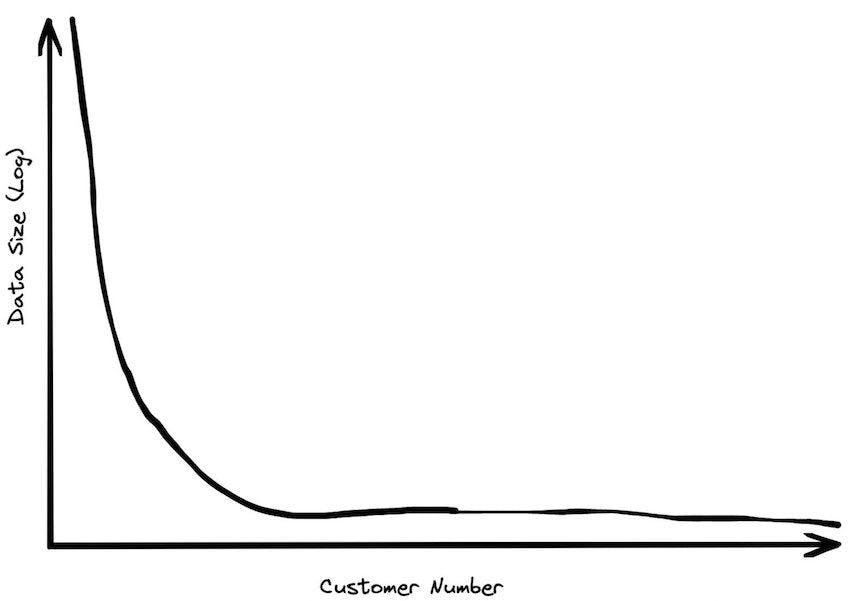
Data sizes grow faster than compute sizes

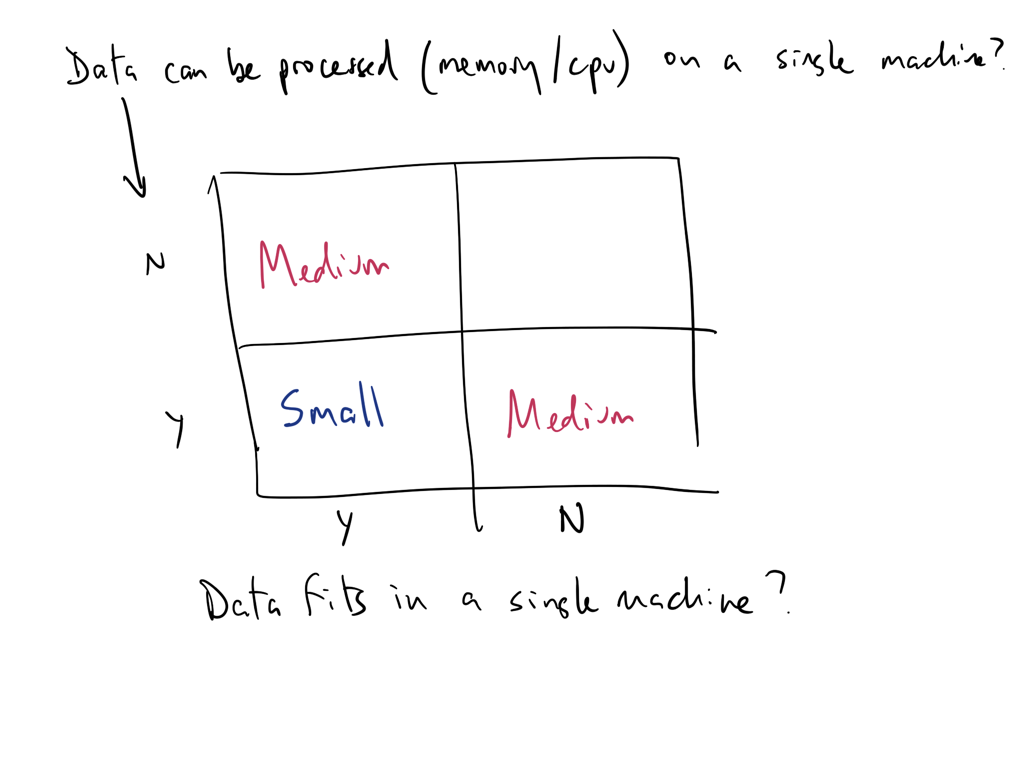
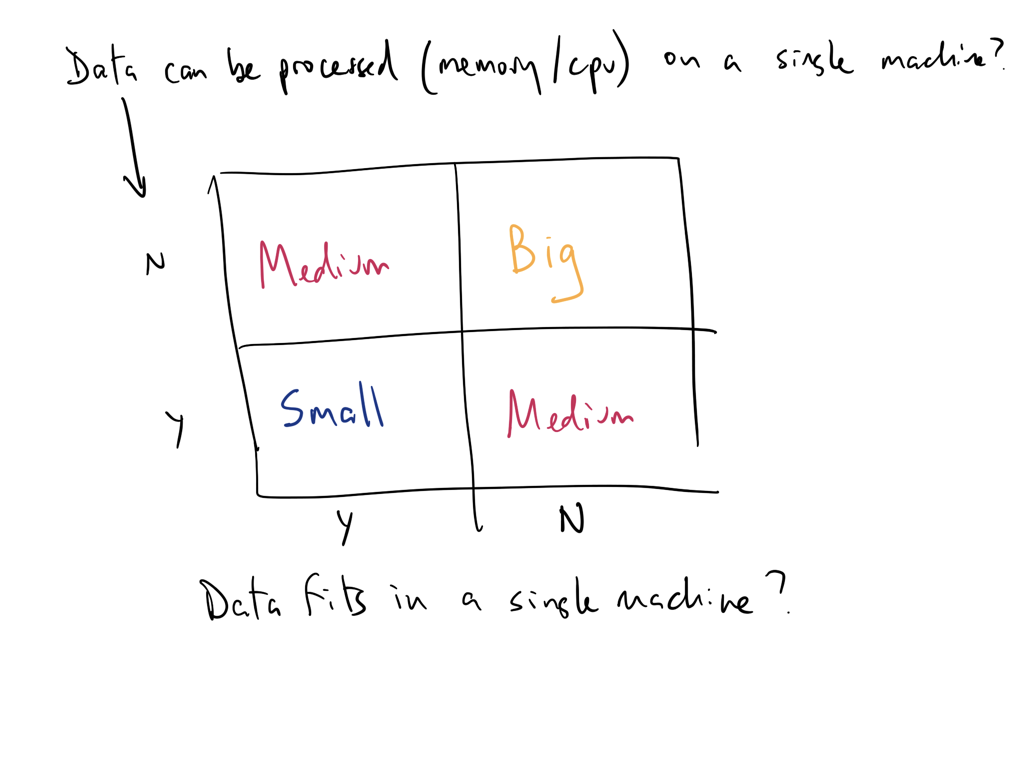
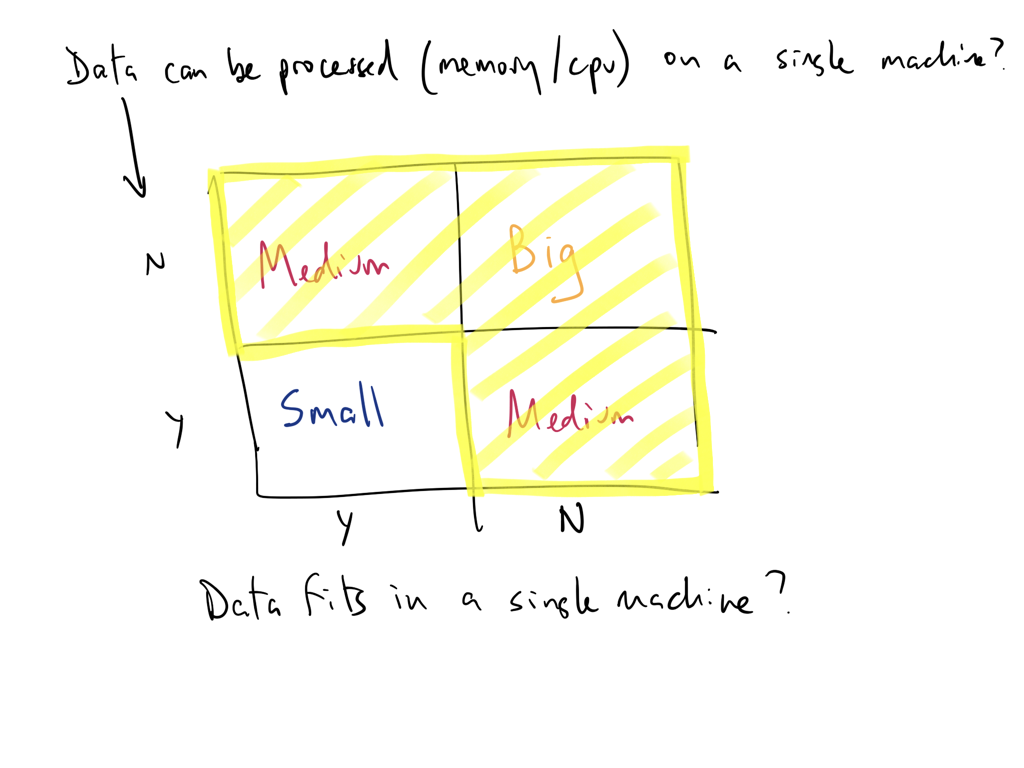
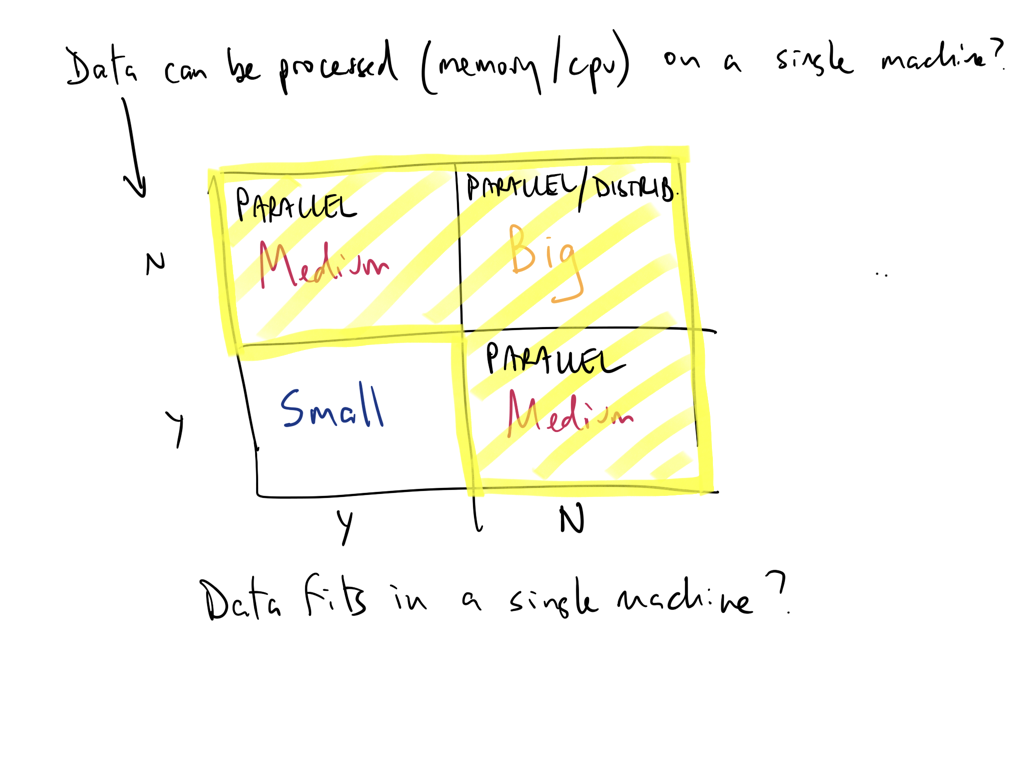
Data workloads can for on modern single machines

You are used to working with single-threaded popular data analysis tools that are memory constrained
![]()
![]()
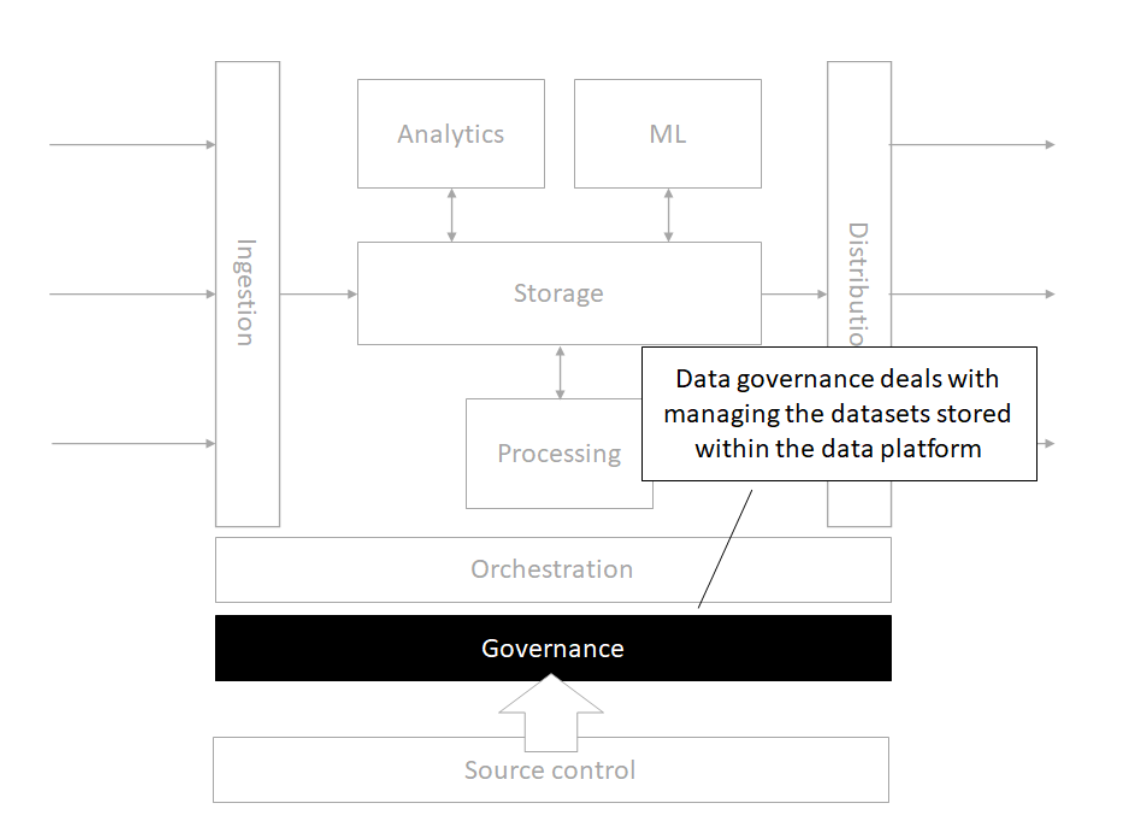
Architecture
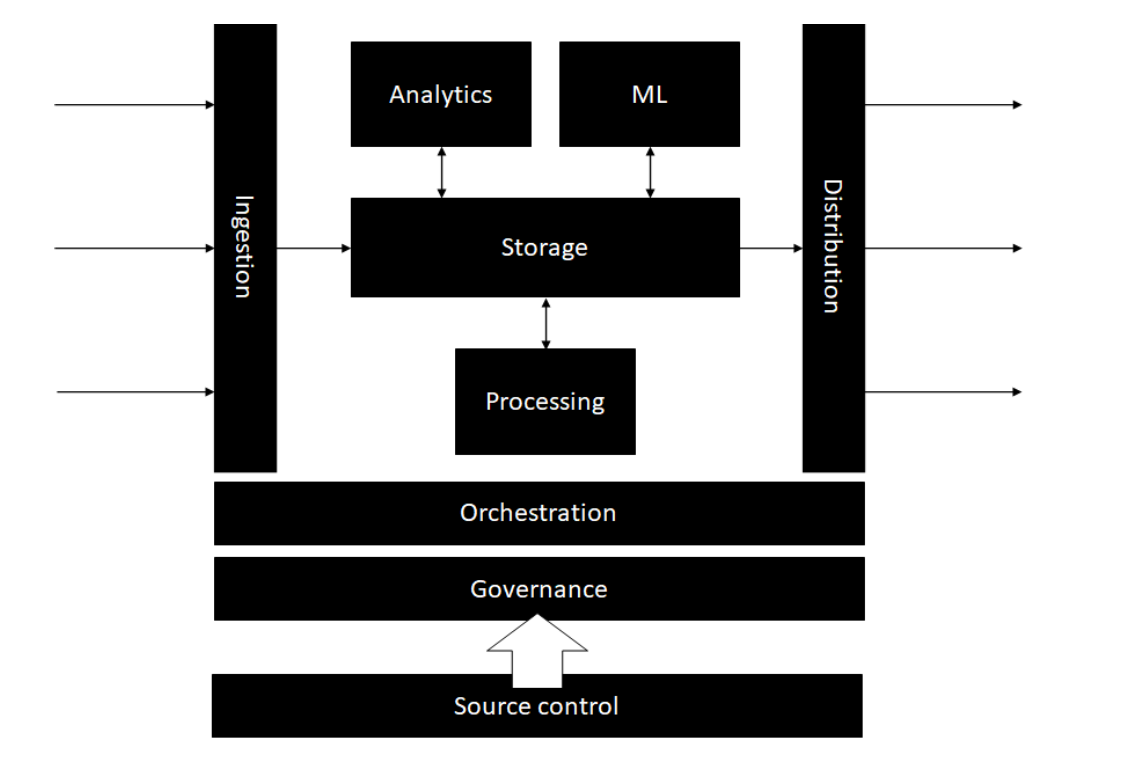
Storage
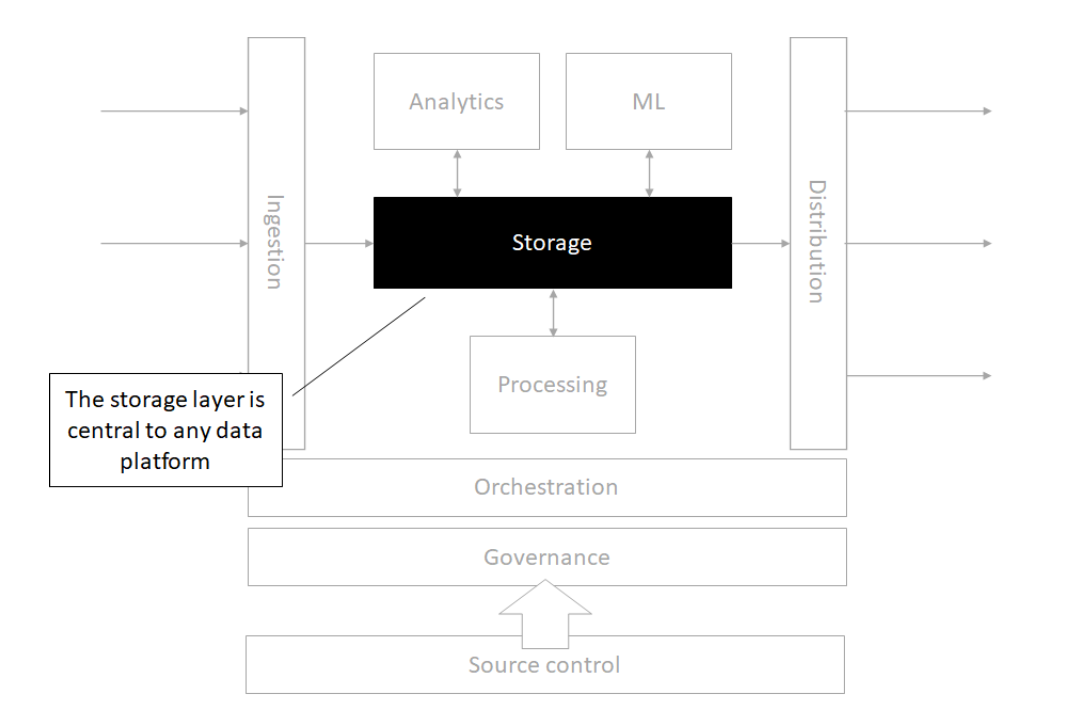
Source control
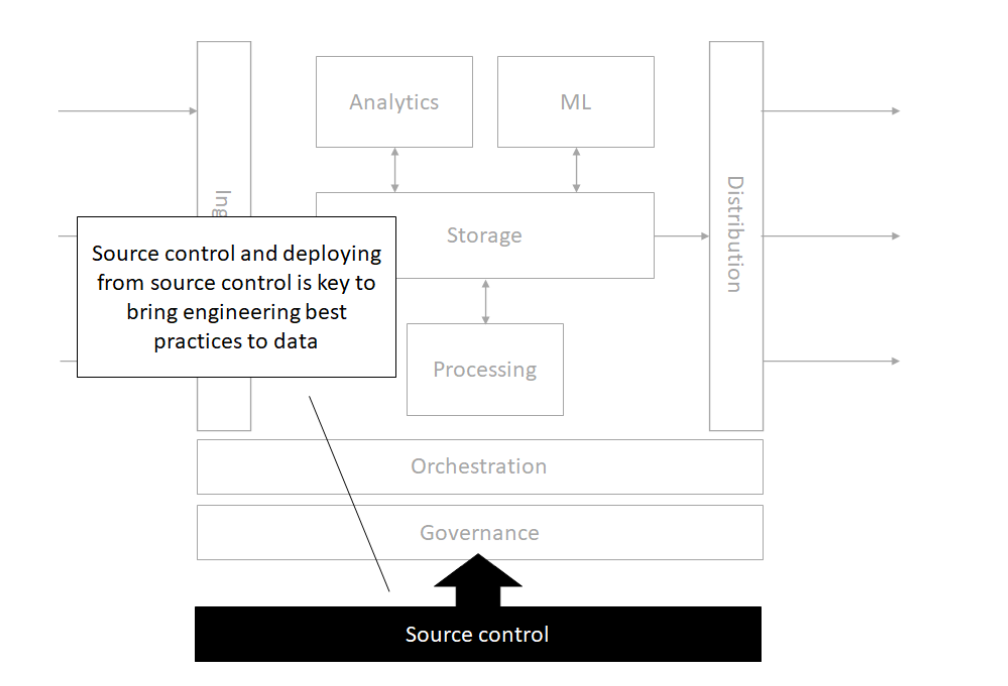
Orchestration
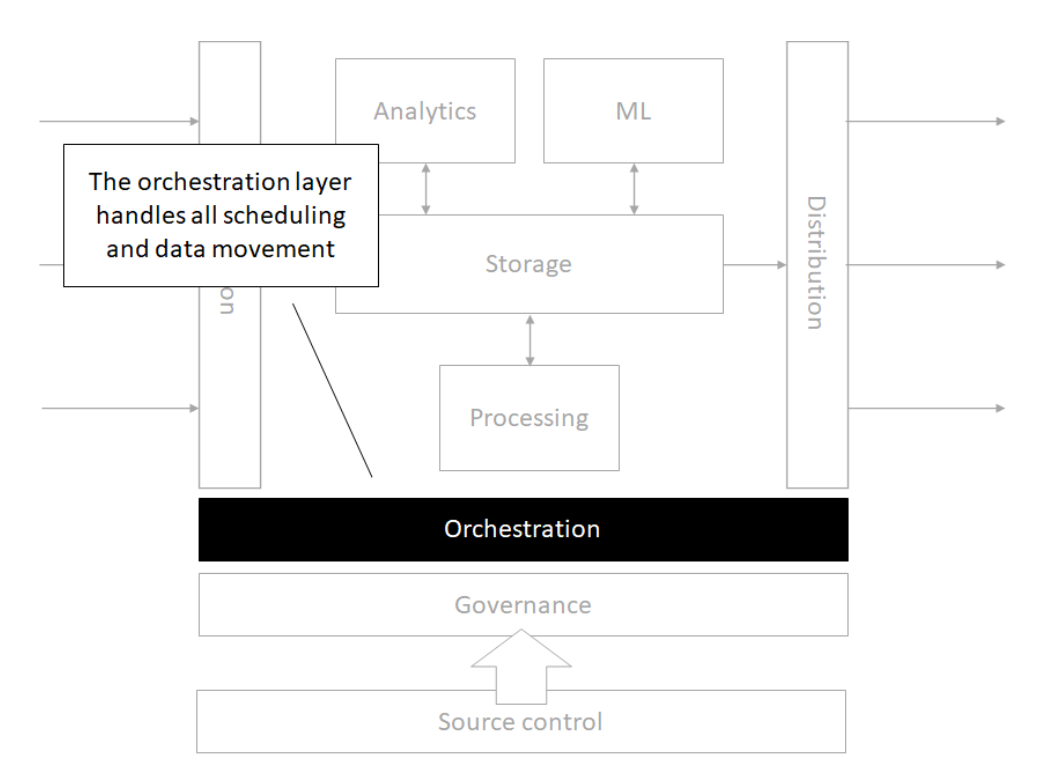
Processing

Analytics
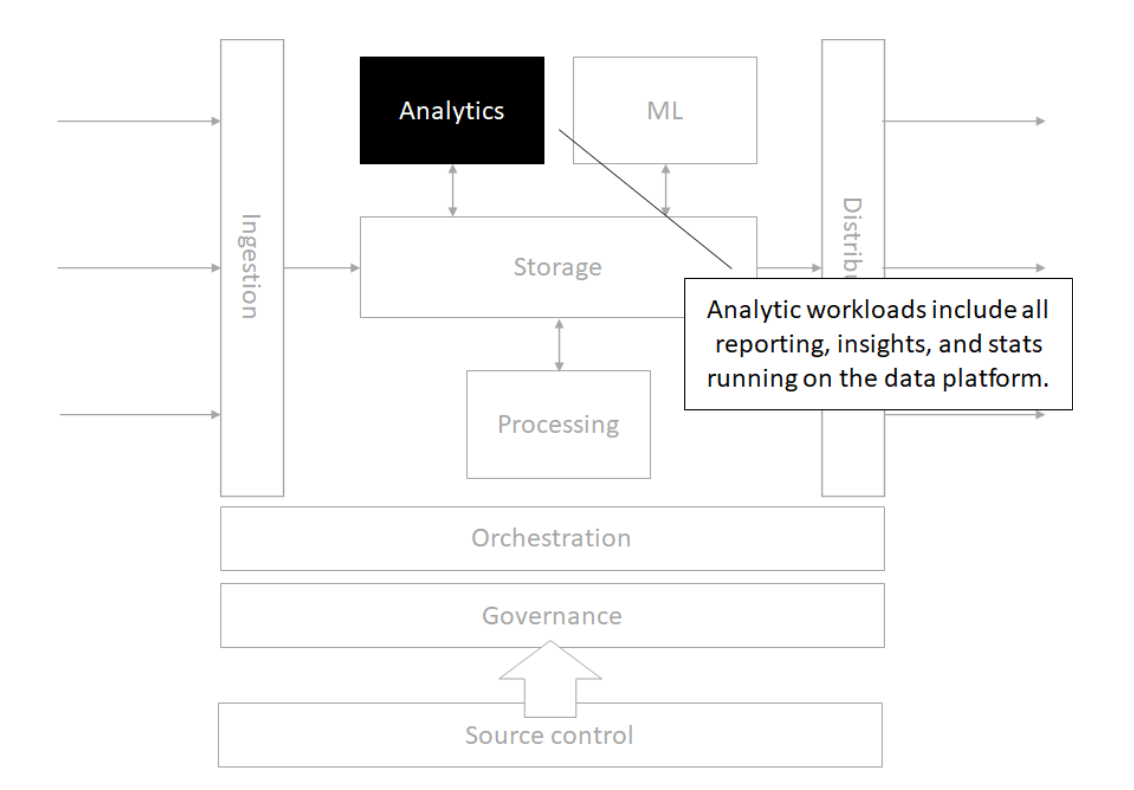
Machine Learning
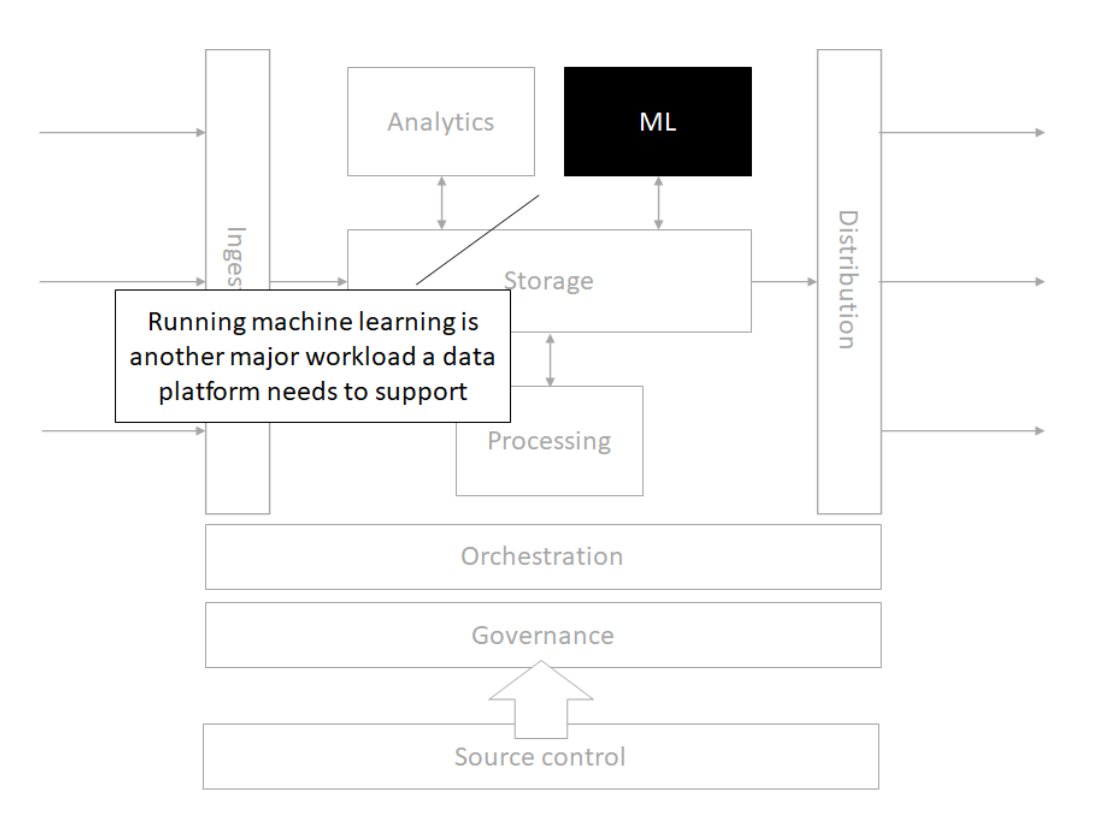
Governance
Yesterday’s hardware for big data processing
The 1990’s solution
One big box, all processors share memory
This was:
- Very expensive
- Low volume
It was all premium hardware. And yet is still was not big enough!

Enter commodity hardware!
Consumer-grade hardware
Not expensive, premium nor fancy in any way
Desktop-like servers are cheap, so buy a lot!
- Easy to add capacity
- Cheaper per CPU/disk
But
Needed more complex software to be able to run on lots of smaller/cheaper machines.

Problems with commodity hardware
Failures
- 1-5% hard drives/year
- 0.2% DIMMs/year
Network speed vs. shared memory
- Much more latency
- Network slower than storage
Uneven performance

Meet Doug Cutting

- In 1997, Doug Cutting started writing the first version of Lucene (a full text search library).
- In 2001, Lucene moves to the Apache Software Foundation, and Mike Cafarella joins Doug and create a Lucene subproject called Nutch, a web-crawler. Nutch uses Lucene to index the contents of a web page as it crawls it.
- Nutch and Lucene were deployed on a single machine (single core processor, 1GB RAM, 8 HDDs ~ 1TB), achieved decent performance, but they needed something that would be scalable enough to be able to index the web.
The Google File System (GFS) Paper

Describes how Google stored its information, at scale, using a reliable and high-available storage system can be built on commodity machines considering that failures are the norm rather than the exception.
GFS is:
- optimized for special application environment
- fault tolerance is built in
- centralized metadata management
- simplify the operation semantics
- decouple I/O and metadata operations
The Google MapReduce Paper

Describes how Google processes data, at scale using MapReduce, a paradigm based on functional programming. MapReduce is an approach and infrastructure for doing things at scale. MapReduce is two things:
- A data processing model named MapReduce
- A distributed, large scale data processing paradigm.
Which provides the following benefits:
- Moves the computation to the data
- Automatic parallelization and distribution
- Fault tolerance
- I/O scheduling
- Integrated status and monitoring
Trivia question: why is it named Hadoop?

![]()
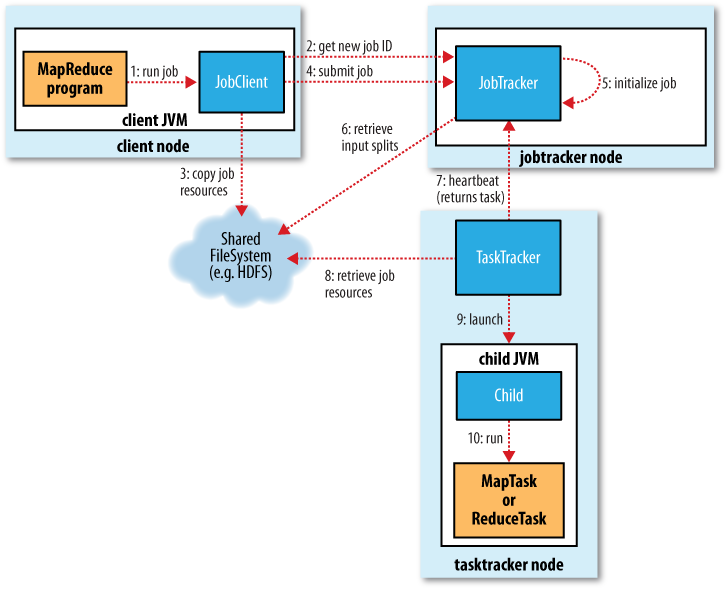
What was Hadoop 1.0: MapReduce Engine and HDFS
MapReduce performs the computations and manages cluster
- The Job Tracker is the master planner
- The Task Tracker runs each task
HDFS stores the data
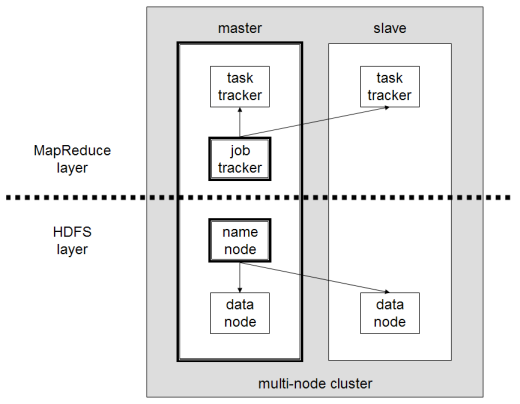
Hadoop 1.0 Problems
- Monolithic
- MapReduce had too many responsibilites
- Assigning cluster resources
- Managing job execution
- Doing data processing
- Interfacing with client applications
- Only supported MapReduce
- Had a single NameNode to manage the cluster (single point of failure)
- Batch oriented and extremely inefficient with iterative queries

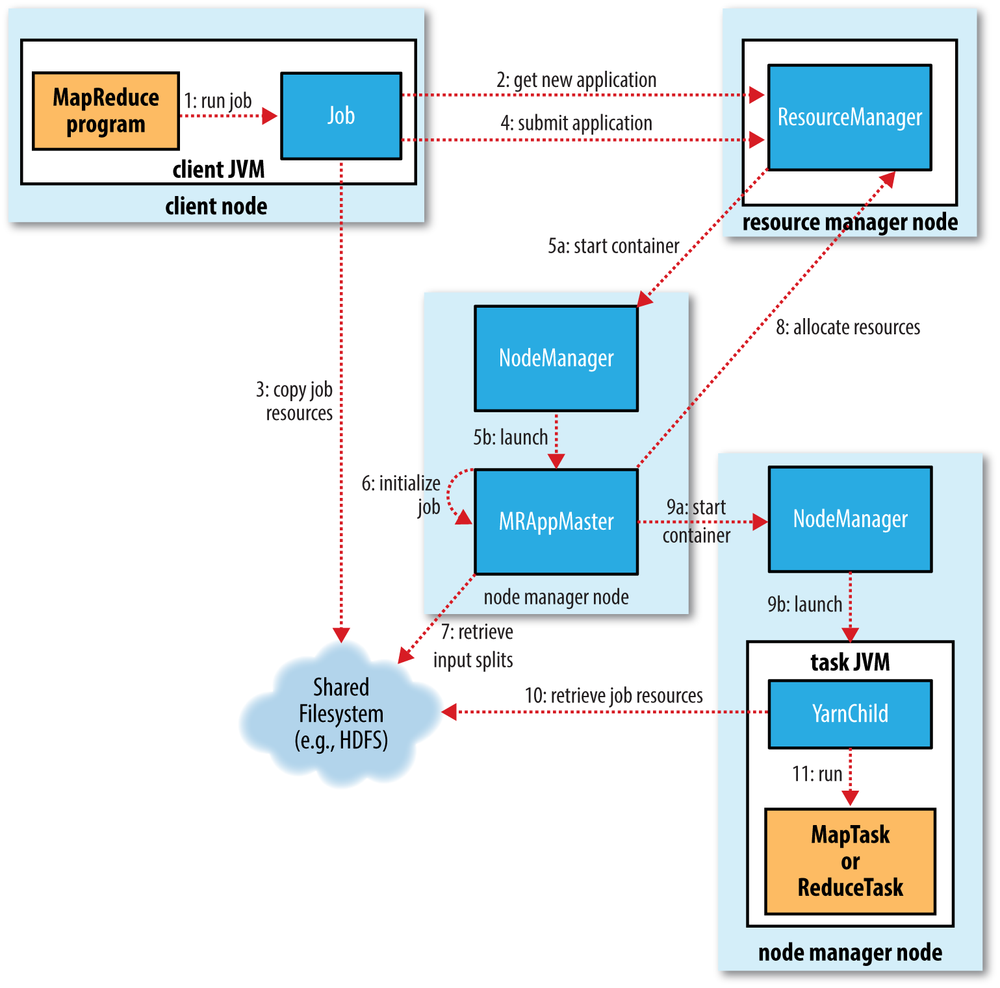
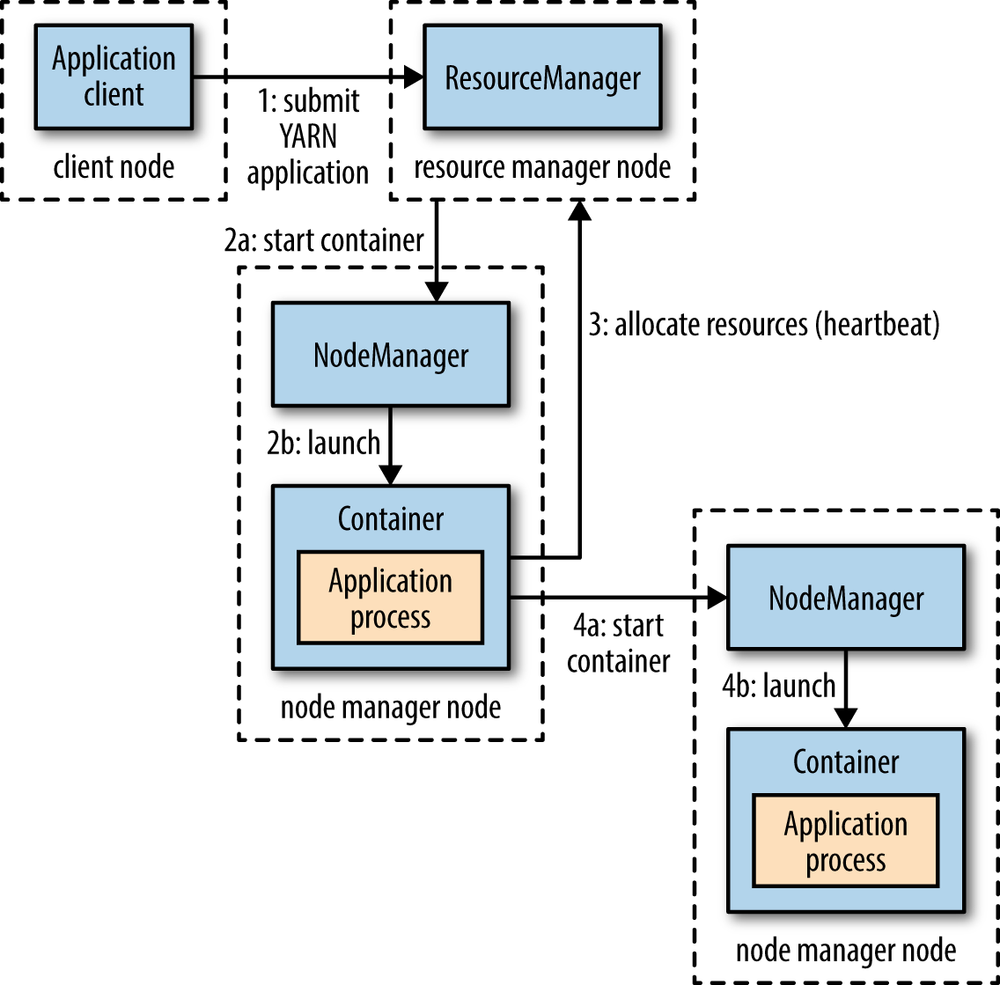
YARN & Hadoop 2.0
- Hadoop 2.0 was released in 2013
- Cluster management capability gets pulled out of MapReduce and becomes YARN (Yet Anothe Resource Negotiator), decoupling cluster operations from data pipeline
- Allowed for other applications to run on a cluster
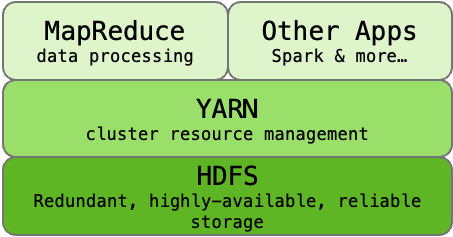
A MapReduce Job (1.0)
A MapReduce Job (2.0+)
How YARN manages the Cluster
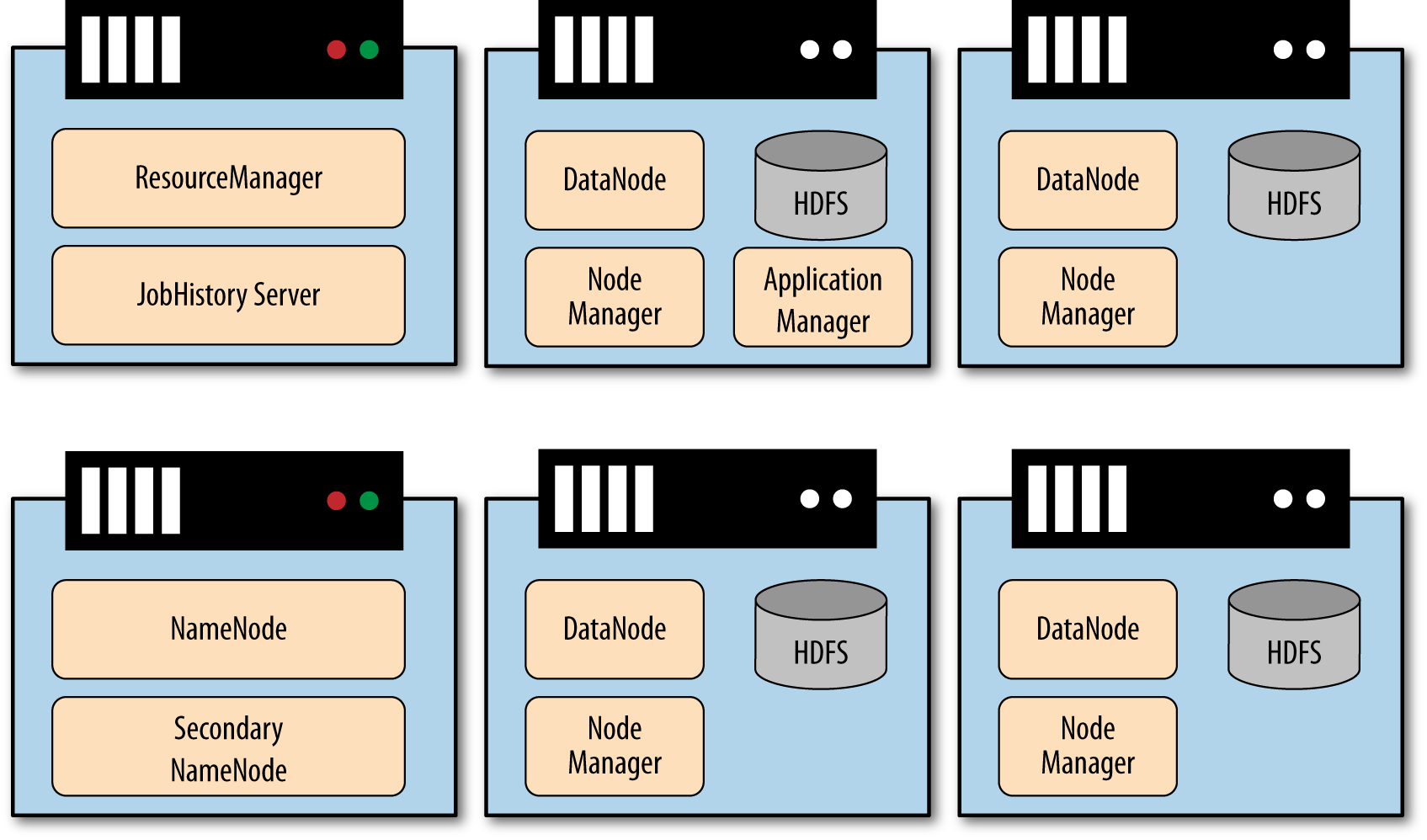
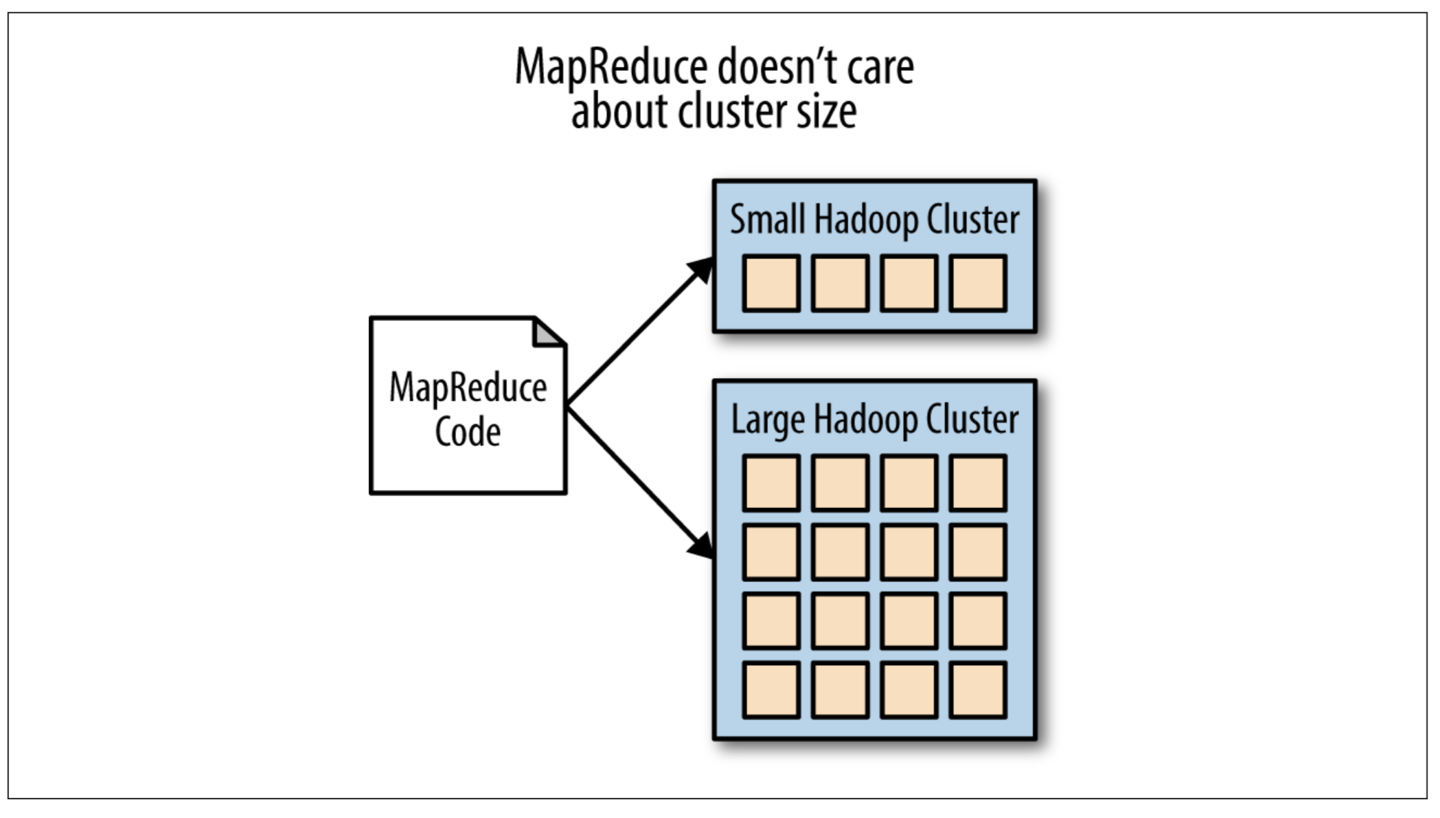
The Hadoop Architecture is Scalable

The Current Hadoop Ecosystem: https://hadoopecosystemtable.github.io/
Terminal
- Terminal access was THE ONLY way to do programming
- No GUIs! No Spyder, Jupyter, RStudio, etc.
- Coding is still more powerful than graphical interfaces for complex jobs
- Coding makes work repeatable
BASH

- Created in 1989 by Brian Fox
- Brian Fox also built the first online interactive banking software
- BASH is a command processor
- Connection between you and the machine language and hardware